[Python] JPEG Encoderを実装しながら追うJPEGのファイル仕様
普段何気なく使っているJPEG(.jpg)がどのような仕組みで圧縮・展開しているかということを調べた。
なおここではJPEGフォーマットの様々な形式の内、ベースライン形式・YCbCrの3要素のものに限定して解説する。
JPEG圧縮の概要
JPEG圧縮は大きく分けて以下の10の工程によって成り立つ。
特に「クロマサブサンプリング」と「量子化」はデータ量を明確に削減するためのプロセスで、圧縮後の画質に大きく影響する。(「色空間変換」と「離散コサイン変換」は浮動小数点数型の誤差程度)
- 画像入力(RGB)
- 色空間変換 (非可逆)
- クロマサブサンプリング (非可逆)
- ブロック分割
- 離散コサイン変換 (非可逆)
- 量子化 (非可逆)
- ジグザグスキャン
- 中間表現
- Huffman符号化
- バイナリ出力
それぞれの工程の詳細を以下に解説する。
画像入力・色空間変換
この記事では以下の画像をJPEGに圧縮する様子を辿っていく。入力画像の形式は縦x横x色数=HxWx3とする。

色空間変換
まずは各ピクセルの色情報をRGB空間からYCbCr空間へと変換する。
\begin{align} \left(\begin{array}{c} Y \\ Cb \\ Cr \end{array}\right) = \left(\begin{array}{ccc} 0.299 & 0.587 & 0.114 \\ -0.16897 & -0.3313 & 0.5 \\ 0.5 & -0.4187 & -0.0815 \end{array}\right) \times \left(\begin{array}{c} R \\ G \\ B \end{array}\right) - \left(\begin{array}{c} 128 \\ 0 \\ 0 \end{array}\right) \end{align}Yはルーマ(輝度を近似した値)を、Cb・Crは色差情報を表す値。
この変換ではY・Cb・Crは負の値となることもあり、それぞれ\([-128, 128)\)の範囲の値を取る。
Y・Cb・Crそれぞれの要素のことをcomponentと呼ぶ。
実際の画像の変換結果は以下のようになる。低い値を黒で、高い値を白で表現する。

クロマサブサンプリング
人の目は明るさに鋭く色彩には鈍いという特性を利用して、色差(Cb・Cr)コンポーネントのサイズを縮小することでデータ量を減らす。縮小された色差情報から復元されたRGB画像を人が見ても元の画像との差はほとんどないように見えるということになる。
縮小率は通常Y=1, Cb・Cr=1/2が使われる。これはJ:a:b=4:2:0という形式で、JPEGが出来る前から放送の分野でよく使われてきた言葉らしい。
縮小率は水平・垂直方向にそれぞれ1/1から1/4倍までの倍率を選ぶことができる。本来は色差情報を間引くための手法ではあるが、輝度(Y)に対して縮小を行うことも可能。
縮小アルゴリズムはEncoderの実装による。
輝度と色差がどれほど人間の目に対して差があるか以下に示す。左の画像は色差のみをサブサンプリングしたJPEGで、右の画像は輝度のみをサブサンプリングしたJPEG。色差をサンプリングした方はほとんど元画像との違いが認識できないのに対して、輝度をサブサンプリングした方がぼやけて見えることがわかる。そういう理由で色差をサンプリングするというのは理にかなっていることになる。


画像データは最終的にECSというバイナリの列に落とし込まれるのだが、その保存はMCUという画像の領域ごとに行われる。MCUの最小単位は8x8pxのブロックで、一つのMCUに含まれる各コンポーネントはRGBに復元するときに同じ座標領域を表すデータである必要があるので、クロマサブサンプリングの比率からMCUのサイズを求めることができる。
例えば4:2:0の場合はYを2x2ブロック、Cbを1x1ブロック、Crを1x1ブロック含む領域が最小のMCUとなるので、MCUのサイズは16x16pxとなる。
クロマサブサンプリングでは縮小する前に端に余剰が発生しないように、MCUのサイズで割り切れるサイズになるまで右端・下端を端の値を繰り返して埋めるという前処理が行われる。
このプロセスの変換結果は以下のようになる(4:2:0の場合)。

ブロック分割・離散コサイン変換
次に離散コサイン変換を行うのだが、離散コサイン変換は8x8の画像を8x8の周波数情報に変換する処理であるため、予め画像を8x8のブロックに分割する。MCUの最小単位が8x8だったのはこのためである。

離散コサイン変換
離散コサイン変換(DCT)では画素ごとの信号情報を8x8のブロック単位で周波数情報に変換する。このプロセスはこの先の量子化と組み合わせて使うためのものであり、量子化プロセスで高周波数部分の情報を減らすことにより最終的なファイルサイズを大きく削減することができる。これは人間の目には画像の高周波数成分のわずかな違いは認識できないという視覚特性に基づいている。
8x8の信号情報のブロック\( s\)を8x8の周波数情報\( S\)に変換する離散コサイン変換は以下のように実行される。
\begin{align} S_{vu} = \sum_{x=0}^{7}\sum_{y=0}^{7}\frac{1}{4}\times C_{u}\cos\left(\frac{(2x+1)u\pi}{16}\right)C_{v}\times\cos\left(\frac{(2y+1)v\pi}{16}\right)\times s_{yx} \end{align} \begin{align} C_{i} = \left\{ \begin{array}{ll} \frac{1}{\sqrt{2}} & (i = 0)\\ 1 & (otherwise) \end{array} \right. \end{align}これはテンソル \( DCT_{vuyx} = \frac{1}{4}\times C_{u}\cos\left(\frac{(2x+1)u\pi}{16}\right)C_{v}\times\cos\left(\frac{(2y+1)v\pi}{16}\right)\) と信号情報ブロック行列 \( s_{xy}\) との畳み込みとなっている。したがって、予めテンソル \( DCT\) を計算しておけば、全てのブロックの離散コサイン変換に同じテンソルを使い回すことができる。
テンソル \( DCT\) は以下のような構造となっている。(縦がvで横がu、更に各ブロック内で縦がyで横がx)

以下の図に離散コサイン変換による具体的な値の変換例を示す。(\( v,u=1,6\) の例)

変換結果の左上(\( u,v=0,0\) )の成分をDC成分(直流成分)と言い、それ以外をAC成分(交流成分)と言う。DC成分は \( [-1024, 1024)\) の範囲の値を取り、AC成分は \( [-512, 512]\) の範囲の値を取る。そのため、DC成分はAC成分と比べて極端な値を取りやすいという性質がある。
量子化
先述の通り、量子化プロセスでは離散コサイン変換の結果の高周波数成分の情報を減らす。
周波数情報の削減は、周波数情報となった各ブロックをを量子化テーブルという行列で割って四捨五入することで実行される。量子化テーブルはコンポーネントごとに定義できて、ファイルごとに定義された量子化テーブルをファイル内に埋め込む必要がある。8x8の量子化テーブルを直接指定することも出来るが、一般的にはQualityを指定してデフォルトの量子化テーブル実数倍することで構成することが多い。
デフォルトの量子化テーブルと、Qualityから倍率(Scale)への変換式(一般的なもの)を以下に示す。 \( QT_{Y}\) は輝度コンポーネントに、 \( QT_{C}\) は色差コンポーネントにそれぞれ適用する。


量子化の結果は以下のようになる。(quality=90の場合)

なおデコーダーでは逆に量子化テーブルの値を掛けて情報を復元する。その際に元の画像の量子化の余りの部分は復元できないので、この量子化は非可逆的なプロセスと言える。
なお、JPEGのエンコードにおいて非可逆的なプロセスはこの量子化が最後となる。言い換えると、この先のプロセスはJPEGの画質には一切影響しないということになる。
ジグザグスキャン
この先のHuffman符号化プロセスの下準備として、量子化後の各ブロックを8x8の行列から一列の配列に並べ直す。JPEGではその際に縦横順番に値を拾って並べるのではなく、低周波数部分から高周波数部分へジグザグに値を拾って並べるという仕様となっている。これは量子化プロセスによって高周波数成分ほど0の値が頻出するという性質があるので、0がなるべく連続するように並べることでHuffman符号化での圧縮率を高めるという狙いがある。
値を拾う具体的な順序は以下の図の通り。

ジグザグスキャンによってブロックは以下のように変換される。

中間表現
Huffman符号化の準備として、ジグザグスキャンで得られた64個の値を中間表現(Intermediate Entropy Coding Representations)に変換する。中間表現への変換手法はDC成分とAC成分で異なる部分があり、DC成分ではDPCM(差分パルス符号変調)という手法を、AC成分ではRLE(ランレングス符号化)という手法を用いる。
DC成分(DPCM)
DC成分は \( [-1024, 1024)\) と値の範囲が広くそのままではHuffman符号化に最適ではない。ここで、DC成分の値は8x8のブロックの平均値の8倍なので隣り合うブロックではその差は微小であることが多いという性質を利用する。DC成分の生の値の代わりに前のブロックからの差分情報を使うことで、値出現頻度に偏りを与えてHuffman符号化に適した形にすることができる。
差を取る順序は以下の図のようにMCU単位で、MCU内では横縦の順に差を取っていく。
なお、最初のブロックのDC成分はそのまま変更しない。
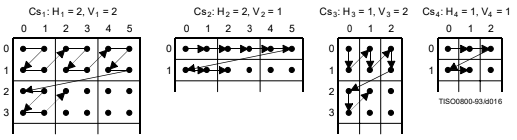
DCPMによって各ブロックのDC成分は以下のようになる(下図の左から中央)。

DCPMの次に、値を中間表現へと変換する(上図の中央から右)。中間表現はSymbolとAdditional bitsの2つの値で構成される値で、以下の式から求められる。
\begin{align} Symbol = Size = \left\{ \begin{array}{ll} \lfloor\log_{2}\left|v\right|\rfloor+1 & (v \neq 0)\\ 0 & (v = 0) \end{array} \right. \end{align} \begin{align} Additional\_bits = \left\{ \begin{array}{ll} v & (0 < v)\\ v + 2^{size} - 1 & (v < 0) \end{array} \right. \end{align}Sizeと対応する「値(\( v\))の範囲」は以下の表のようになっている。

AC成分(RLE)
AC成分も同様の中間表現へと変換していく。
AC成分は量子化とジグザグスキャンによって0が連続やすい形式になっているので、ランレングス符号化という手法を用いてデータを圧縮する。連続する0の個数(ランレングス)をカウントして、次に現れる0以外の値の上位4bitに付加し、下位4bitはDC成分と同様にSizeの値を記録するという手法。DCTの解説で触れたように、AC成分は \( [-512, 512]\) の範囲の値しか取らないので、Sizeは最大でも0x0A。上位4bitに別の情報を書き込んでも問題ない。
更にランレングス符号化では、16連続の0をZRL(0xF0)というSymbolに、ブロックの末尾に連続する0をEOB(0x00)というSymbolに変換する。
\begin{align} Symbol &= RRRRSSSS, \\ RRRR&: \textrm{Run-Length}, \\ SSSS&: \textrm{Size} \end{align}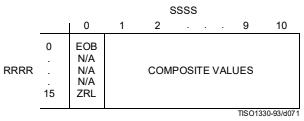
RLEによって各ブロックのAC成分は以下のように変換される。

Huffman符号化
次にHuffman符号化で中間表現のSymbol部分を符号化する。
Additional bits部分はそのまま変換しない。
中間表現プロセスの出力において、DC成分のSymbolは最大12種類、AC成分のSymbolは最大162種類の値を取る。単純にバイナリーに保存することを考えれば、それぞれ4bit・16bitの値としてSymbolをそのまま保存する方法が考えられる。
しかし、それぞれのSymbol値は出現頻度に大きな偏りがあるので、出現頻度の高いSymbolには短い符号を割り当て、その代わりに出現頻度の低いSymbolには長い符号を割り当てるという方法を用いることができればより圧縮できる。
これを実現する手法がHuffman符号化である。Huffman符号化ではある符号の先頭から途中までが別の符号を表すという符号の重複がないので、先頭から読んでいけば符号の長さがわからなくても必ず一意に復号できるようになっている。
Huffman符号化ではHuffmanテーブルというSymbolと符号の対応関係を表すデータが生成され、その対応に基づいてエンコード・デコードが実行される。
JPEGではファイルの中にそのファイルで作られたHuffmanテーブルを埋め込む必要があるのだが、JPEGに保存できるHuffmanテーブルにはデータサイズの制限があり、符号は最長で16bitまでの値しか取れない。したがって、JPEGの圧縮ではHuffman符号化を単に適用すれば良いのではなく、16bitに制限されたLength-Limited Huffman Codesを実行しなければならない。
Package-Mergeアルゴリズム
Length-Limited Huffman Codesの解法の一つがPackage-Mergeアルゴリズム。なぜPackage-Mergeアルゴリズムで最適なHuffmanテーブルが構成できるのかという証明はさておき、アルゴリズムの実行方法を解説する。
Package-Mergeアルゴリズムでは、まず符号化したい各シンボルの出現回数を数え上げてリストを作る。その後、PackageステップとMergeステップを(符号化したい最長のbit数 - 1)回繰り返すことでHuffmanテーブルを構築する。
Packageステップでは、リストをカウントが低い順に並べ替えて、低い順に2つずつ要素を合成して新しいリストを作る。新しい要素は合成元の要素が含む全てのシンボル(シンボルの種類が重複する場合も含む)と、合成元のカウントを合計した値を保持する。2つずつのペアを作る際に余った要素は処理せず無視する。
Mergeアルゴリズムでは、現在のリストと最初のリストを結合する。更にリストの長さが2の倍数でない場合は出現回数が最大の要素を削除する。
最後のMergeステップまで進んだら、リストの全要素が含む各シンボル数を数え上げる。すると、Symbol毎のカウントがHuffman符号の長さと等しくなる。符号長の短い順にHuffman符号を割り当てていけばHuffmanテーブルが完成する。
Pakcage-Mergeアルゴリズムの実行例を以下の図に示す。
シンボル数6, 最長4bitの場合。制限なしのHuffman符号化ではAが5bitの符号となってしまうが、Package-Mergeアルゴリズムを使うことで全ての符号を4bit以下に抑えることができる。


JPEGにおけるHuffman符号化
JPEGでは1のみで構成される符号は扱うことができない。そこで、Huffman符号化の際に予め出現回数0の仮の符号を与えてPackage-Mergeアルゴリズムを実行し、Huffmanテーブルを構成する際には仮符号を無視することで、1のみで構成される符号が現れないHuffmanテーブルを作ることができる。
JPEGのHuffmanテーブルは、DC成分・AC成分でそれぞれ構築され、更にコンポーネントごとに別のHuffmanテーブルを使うように指定することができる。
YのDC成分・YのAC成分・CbCrのDC成分・CbCrのAC成分の4つのHuffmanテーブルに分けるのが一般的。
Huffmanテーブルを構築したら、中間表現のSymbol部分をHuffman符号に置換して、blockを一列のバイナリ列に変換する。
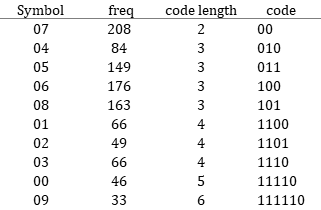
実際のHuffmanテーブルと、Symbolの置換結果は以下のようになる。(YのDC成分の場合)
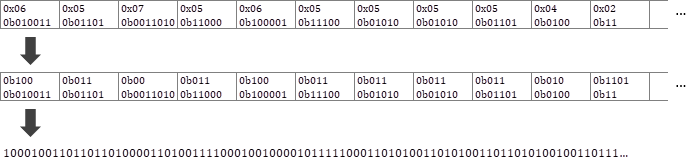
バイナリ出力
最後にここまでで構築したデータをファイルに出力する。
JPEGのバイナリは複数のセグメントによって構成され、必須セグメントのみ見れば一般的には先頭から順にSOI・DTQ(Y)・DTQ(CbCr)・SOF0・DHT(DC,Y)・DHT(AC,Y)・DHT(DC,CbCr)・DHT(AC,CbCr)・SOS・ECS・EOIという構成になっていることが多い。
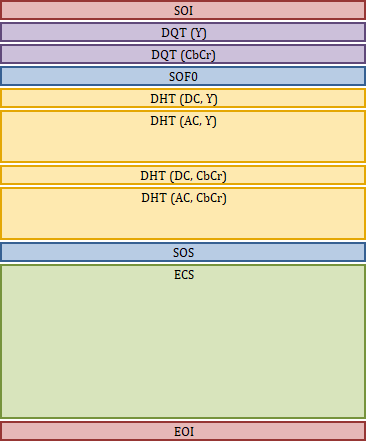
これらJPEGの必須セグメントとその具体的な値の書き込み方を以下で追っていく。
SOI (start-of-image)
SOIには固定値のSOIマーカーだけを記録する。
DQT (define-quantization-tables)
DQTには量子化テーブルを記録する。
- \( Lq\) はマーカーを除いたセグメントの長さ。
- \( Pq\) は量子化テーブルの精度(各成分のbit長)。0なら8bitを意味し、1なら16bitを意味する。
- \( Tq\) は量子化テーブルのID。
- \( Q_{k}\) は量子化テーブルの各要素の値。ジグザグスキャンの順序で記録する。

SOF0 (start-of-frame (baseline DCT process frame))
SOF0にはフレームに必要な情報を記録する。
- \( Lf\) はマーカーを除いたセグメントの長さ。
- \( P\) はサンプル精度。各コンポーネントの各ピクセルが何bitの値を持つかという数値。
- \( Y\) は画像の高さ。
- \( X\) は画像の幅。
- \( Nf\) はコンポーネントの数
- この先は各コンポーネントに対してそれぞれサンプリング係数と使用する量子化テーブルのIDを記録する。
- \( C_{i}\) はコンポーネントID。
- \( H_{i}\) は水平のサンプリング係数。1つのMCUに幾つのブロックが横方向に含まれているかという値。
- \( V_{i}\) は垂直のサンプリング係数。1つのMCUに幾つのブロックが縦方向に含まれているかという値。
- \( Tq_{i}\) は使用する量子化テーブルのID。

4:2:0の場合、YはMCUにブロックが2x2個、Cb・CrはMCUにブロックが1x1個。
したがって\( H_{i}, V_{i}\)はYが22, Cb・Crが11となる。
DHT (define-Huffman-tables)
DHTにはHuffmanテーブルを記録する。
- \( Lh\) はマーカーを除いたセグメントの長さ。
- \( Tc\) はテーブルクラス。0ならDC成分を意味し、1ならAC成分を意味する。
- \( Lh\) はテーブルのID。
- \( L_i\) はHuffmanテーブルに含まれる長さがiの符号の数。
- \( V_i\) はHuffmanテーブルのシンボル。割り当てられた符号の順に記録する。

例えば先程の例で出てきた以下のHuffmanテーブルについて考える。
長さが1の符号は0個, 長さが2の符号は1個, 長さが3の符号は4個, …, 長さが15の符号は0個となっているので、\( L_i\) 部分は以下のようになる。
00 01 04 03 01 01 00 00 00 00 00 00 00 00 00 00
そして、\( V_i\) 部分はSymbolをそのまま書き込むので以下のようになる。
07 04 05 06 08 01 02 03 00 09
これらを繋げて最終的なDHTセグメント全体は以下のようになる。
FF C4 00 1D 00 00 01 04 03 01 01 00 00 00 00 00 00 00 00 00 00 07 04 05 06 08 01 02 03 00 09
SOS (start-of-scan)
- \( Ls\) はマーカーを除いたセグメントの長さ。
- \( Ns\) はコンポーネントの数。
- この先は各コンポーネントに対してそれぞれ使用するHuffmanテーブルのIDを記録する。
- \( Cs_i\) はコンポーネントID。
- \( Td_i\) はDC成分に使用するHuffmanテーブルID。
- \( Ta_i\) はAC成分に使用するHuffmanテーブルID。
- 以下はベースライン方式では"00 3F 00"で固定の値。(プログレッシブ方式やロスレス方式で利用する)
- \( Ss\) : Start of spectral or predictor selection.
- \( Se\) : End of spectral selection.
- \( Ah\) : Successive approximation bit position high.
- \( Al\) : Successive approximation bit position low or point transform.
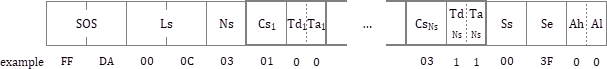
ECS (entropy-coded segment)
ECSはSOSセグメントの直後に続くという決まりがあり、マーカーなどの情報はなく生のデータがそのまま格納される。
書き込みの順序はMCU毎にコンポーネント順。一つのMCUが記録されたら更に次のMCUという風に記録する。このような記録形式をインターリーブ形式と言う。
例えばYCbCrの4:2:0の場合は、Y→Y→Y→Y→Cb→Cr→Y→Y→Y→Y→Cb→Cr→…という順でブロックを記録していく。
全ブロックを結合して1Byteに満たない余剰が出た場合は、データのサイズがByte単位になるように末尾を1で埋める。Huffman符号化で1のみの符号が使えなかったのは、この1埋めを符号と誤認しないようにするためだった。
更にデータ内の値"FF"がマーカーと混同されないように、"FF"を"FF00"に置換する。これをByte stuffingと言う。
EOI (end-of-image)
EOIには固定値のEOIマーカーだけを記録する。
Encoderの実装
実装
だいたいのケースで動くと思うが、DQTが2バイトの場合(quality < 25)に対応していないなど不完全な部分もある。
import numpy as np
from PIL import Image
class Encoder:
MAT_RGB_TO_YCBCR = np.array([
[ 0.299, 0.587, 0.114 ],
[-0.16897, -0.3313, 0.5 ],
[ 0.5, -0.4187, -0.0815],
])
MAT_DCT = np.array(
[
[
[
[
(1 if k == 0 else np.sqrt(2))*np.cos(np.pi/8*(i+1/2)*k) * (1 if l == 0 else np.sqrt(2))*np.cos(np.pi/8*(j+1/2)*l) / 8
for j in range(8)
] for i in range(8)
] for l in range(8)
] for k in range(8)
]
)
ZIGZAG_ORDER = np.array([
0, 1, 8, 16, 9, 2, 3, 10, 17, 24, 32, 25, 18, 11, 4, 5,
12, 19, 26, 33, 40, 48, 41, 34, 27, 20, 13, 6, 7, 14, 21, 28,
35, 42, 49, 56, 57, 50, 43, 36, 29, 22, 15, 23, 30, 37, 44, 51,
58, 59, 52, 45, 38, 31, 39, 46, 53, 60, 61, 54, 47, 55, 62, 63])
QT_BASE = [
np.array([
[16, 11, 10, 16, 24, 40, 51, 61],
[12, 12, 14, 19, 26, 58, 60, 55],
[14, 13, 16, 24, 40, 57, 69, 56],
[14, 17, 22, 29, 51, 87, 80, 62],
[18, 22, 37, 56, 68,109,103, 77],
[24, 35, 55, 64, 81,104,113, 92],
[49, 64, 78, 87,103,121,120,101],
[72, 92, 95, 98,112,100,103, 99],
], dtype=np.float64),
np.array([
[17, 18, 24, 47, 99, 99, 99, 99],
[18, 21, 26, 66, 99, 99, 99, 99],
[24, 26, 56, 99, 99, 99, 99, 99],
[47, 66, 99, 99, 99, 99, 99, 99],
[99, 99, 99, 99, 99, 99, 99, 99],
[99, 99, 99, 99, 99, 99, 99, 99],
[99, 99, 99, 99, 99, 99, 99, 99],
[99, 99, 99, 99, 99, 99, 99, 99],
], dtype=np.float64),
]
def __init__(self,
sampling_rate=((2, 2), (1, 1), (1, 1)), # (h, v)
qt_id=(0, 1, 1),
qt_list=None,
ht_id=((0, 0), (1, 1), (1, 1)), # (DC, AC)
quality=90 # 1 - 100
):
self.sampling_rate = sampling_rate
h_max = 0
v_max = 0
for h, v in sampling_rate:
if h_max < h:
h_max = h
if v_max < v:
v_max = v
self.mcu_size = (h_max, v_max)
self.qt_id = qt_id
if qt_list is not None:
self.qt_list = qt_list
else:
self.qt_list = [
self.__quantize_table(qt, quality) for qt in self.QT_BASE
]
self.ht_id = ht_id
def __call__(self, path):
result = {
'path': path
}
# 1. 画像読み込み
x = np.array(Image.open(result['path']))
result['rgb'] = x
result['size'] = x.shape[:2]
# 2. 色空間変換
x = np.einsum('ic,hwc->hwi', self.MAT_RGB_TO_YCBCR, x)
x += np.array([-128, 0, 0])
result['ycbcr'] = x
# 3. クロマサブサンプリング
x = self.subsample(x, self.sampling_rate, self.mcu_size)
result['subsampled'] = x
# 4. ブロック分割
x = tuple([self.block_split(component) for component in x]) # Nx8x8, Nx8x8, Nx8x8
result['blocks'] = x
# 5. 離散コサイン変換
x = tuple([np.einsum('klij,nmij->nmkl', self.MAT_DCT, component) for component in x])
result['dct_blocks'] = x
# 6. 量子化
x = tuple([self.quantize(x[i], self.qt_list[self.qt_id[i]]) for i in range(3)])
result['quantized_blocks'] = x
# 7. ジグサグスキャン
x = tuple([self.zigzag_scan(component) for component in x]) # NvxNhx8x8 -> NvxNhx64
result['scanned_blocks'] = x
# 8. Intermediate Entropy Coding Representationsへの変換(DPCM, RLE=ランレングス符号化)
x = self.symbolize(x, self.sampling_rate)
result['symbolized_blocks'] = x
# 9. Huffman符号化
x, ht = self.huffman_coding(x, self.ht_id)
result['ecs_blocks'] = x
result['huffman_table'] = ht
# 10. ECS
x = self.make_ecs(x, self.sampling_rate)
result['ecs'] = x
return result
@staticmethod
def subsample(x, sampling_rate, mcu_size):
h_max, v_max = mcu_size
component_list = []
for c in range(3):
component = x[:, :, c]
component = Encoder.__pad(component, mcu_size) # 端の値で埋める
height, width = component.shape
h, v = sampling_rate[c]
ssh = h_max // h # 何pxを1pxに縮小するか
ssv = v_max // v
new_component = []
# 平均画素法
for i in range(0, height, ssv):
row = []
for j in range(0, width, ssh):
row.append(np.average(component[i:i+ssv, j:j+ssh])) # 区画ごとに平均を取る
new_component.append(row)
component_list.append(np.array(new_component))
return tuple(component_list)
@staticmethod
def __pad(x, mcu_size):
height, width = x.shape
uh, uv = mcu_size
uh *= 8 # MCUのpixelサイズ
uv *= 8
pad_h = 0
pad_v = 0
if width % uh > 0:
pad_h = uh - width % uh
if height % uv > 0:
pad_v = uv - height % uv
x = np.pad(x, [(0, pad_v), (0, pad_h)], 'edge') # 端の値で埋める
return x
@staticmethod
def block_split(x):
height, width = x.shape
y = []
for i in range(0, height, 8):
row = []
for j in range(0, width, 8):
row.append(x[i:i+8, j:j+8])
y.append(row)
return np.array(y) # NvxNhx8x8
@staticmethod
def __quantize_table(qt_orig, quality):
scale_factor = (100 - quality) / 50 if quality >= 50 else 50 / quality # 25未満のときに注意
qt = np.rint(qt_orig * scale_factor).astype(np.uint8) # 四捨五入
qt[qt < 1] = 1
return qt
@staticmethod
def quantize(x, qt):
x = np.rint(x / qt) # Nx8x8 / 8x8
return x.astype(np.int16)
@staticmethod
def zigzag_scan(x):
nv, nh, _, _ = x.shape
x = x.reshape([nv, nh, 64])
x = np.transpose(x, (2, 0, 1)) # 64xNvxNh
x = x[Encoder.ZIGZAG_ORDER]
return np.transpose(x, (1, 2, 0))
@staticmethod
def symbolize(x, sampling_rate):
x = [np.copy(component) for component in x]
# DCを差分情報に変換
for c, component in enumerate(x):
h, v = sampling_rate[c]
nv, nh, _ = component.shape
prev_value = 0
for i in range(0, nv, v):
for j in range(0, nh, h):
for i2 in range(v):
for j2 in range(h):
value = component[i+i2, j+j2, 0]
component[i+i2, j+j2, 0] = value - prev_value
prev_value = value
# blockごとに(symbol, additional_bits)の配列に変換する
symbolized = [
[
[
Encoder.__symbolize_block(block) for block in row
] for row in component
] for component in x
]
return symbolized
@staticmethod
def __symbolize_block(block):
def hex_symbol(x, zfill=1):
return hex(x)[2:].upper().zfill(zfill)
s_block = []
# DC
size, bits = Encoder.__value_to_bits(block[0])
symbol = hex_symbol(size, zfill=2)
s_block.append((symbol, bits))
# AC
# 先にEOBを決めておく
eob_len = 0 # 末尾に連続する0の個数
while eob_len < 63:
if block[-eob_len-1] != 0:
break
else:
eob_len += 1 # iが63になったらループを抜ける
run_length = 0
for value in (block[1:-eob_len] if eob_len > 0 else block[1:]):
if value == 0:
run_length += 1
if run_length == 16:
# 0が16回続いたらZRLを追加してランレングスをリセット
s_block.append(('F0', ''))
run_length = 0
else:
size, bits = Encoder.__value_to_bits(value)
symbol = hex_symbol(run_length) + hex_symbol(size)
s_block.append((symbol, bits))
run_length = 0
if eob_len > 0:
# blockが1つ以上の0で終わっているならEOBを追加
s_block.append(('00', ''))
return s_block
@staticmethod
def __value_to_bits(v):
if v == 0:
size = 0
bits = ''
else:
# 2^(size-1) <= |v| < 2^size なるsizeを探す
abs_v = v if v > 0 else -v
size = 1
while abs_v > 1:
abs_v = abs_v >> 1
size += 1
if v < 0:
v += 2**size - 1
bits = bin(v)[2:].zfill(size)
return size, bits
@staticmethod
def huffman_coding(x, ht_id):
# DCとACを分離してそれぞれ1つのリストにまとめる
symbol_list = []
for component in x:
cd_list = []
ac_list = []
for row in component:
for block in row:
cd_list.append(block[0])
ac_list += block[1:]
symbol_list.append((cd_list, ac_list))
# Huffmanテーブル番号 -> コンポーネント番号のリスト
dc_htid_cid = {}
ac_htid_cid = {}
for i, (dc_id, ac_id) in enumerate(ht_id):
if dc_id not in dc_htid_cid:
dc_htid_cid[dc_id] = []
dc_htid_cid[dc_id].append(i)
if ac_id not in ac_htid_cid:
ac_htid_cid[ac_id] = []
ac_htid_cid[ac_id].append(i)
# Huffmanテーブル番号 -> Huffmanテーブル
dc_ht = {}
ac_ht = {}
for key, value in dc_htid_cid.items():
dc_list = []
for cid in value:
dc_sub, _ = symbol_list[cid]
dc_list += [ir[0] for ir in dc_sub] # intermediate representationから符号のみを抽出
dc_ht[key] = Encoder.__build_huffman_table(dc_list)
for key, value in ac_htid_cid.items():
ac_list = []
for cid in value:
_, ac_sub = symbol_list[cid]
ac_list += [ir[0] for ir in ac_sub]
ac_ht[key] = Encoder.__build_huffman_table(ac_list)
# 符号に置換
ecs_blocks = []
for i, component in enumerate(x):
dc_id, ac_id = ht_id[i]
ecs_blocks.append([
[
Encoder.__replace_symbol(block, dc_ht[dc_id], ac_ht[ac_id])
for block in row
] for row in component
])
return ecs_blocks, {
'dc': dc_ht,
'ac': ac_ht,
}
@staticmethod
def __build_huffman_table(symbol_list, max_bits=16, extra_symbol=True):
# 個数を数え上げる
counter = {} # Symbol -> 出現回数
for s in symbol_list:
if s not in counter:
counter[s] = 1
else:
counter[s] += 1
# Package-Mergeアルゴリズム
# (使用回数, 使用シンボルリスト)のリストを作る
l = []
for key, value in counter.items():
l.append((value, [key]))
if extra_symbol:
# 1だけで構成されるシンボルは使えないので、Huffmanテーブルを作る前に1つ余計なシンボルを入れておく
l.append((0, []))
merge = l
for level in range(1, max_bits):
merge.sort() # カウントの少ない順にソート(tupleのそれぞれの要素を自動で見てくれる)
# package
package = []
for j in range(1, len(merge), 2): # 余った要素は無視する
count1, symbols1 = merge[j-1]
count2, symbols2 = merge[j]
package.append((count1+count2, symbols1+symbols2))
# merge
merge = l + package
if len(merge) % 2 == 1:
merge = merge[:-1]
code_length = {} # Symbol -> 符号長
for key in counter:
code_length[key] = 0
for _, symbols in merge:
for s in symbols:
code_length[s] += 1
# Huffmanテーブルを構築
huffman_table = {} # Symbol -> 符号
code_list = [(length, symbol) for symbol, length in code_length.items()]
code_list.sort()
bits = 0
prev_length = 1
for length, symbol in code_list:
bits <<= length - prev_length
prev_length = length
huffman_table[symbol] = bin(bits)[2:].zfill(length)
bits += 1
return huffman_table
@staticmethod
def __replace_symbol(block, dc_ht, ac_ht):
ecs_block = ''
symbol, additional_bits = block[0]
ecs_block += dc_ht[symbol]
ecs_block += additional_bits
for symbol, additional_bits in block[1:]:
ecs_block += ac_ht[symbol]
ecs_block += additional_bits
return ecs_block
@staticmethod
def make_ecs(x, sampling_rate):
mcu_len_v = len(x[0]) // sampling_rate[0][1]
mcu_len_h = len(x[0][0]) // sampling_rate[0][0]
ecs_bin = ''
for i in range(mcu_len_v):
for j in range(mcu_len_h):
for c, component in enumerate(x):
h, v = sampling_rate[c]
for i2 in range(v):
for j2 in range(h):
ecs_bin += component[i*v+i2][j*h+j2]
if len(ecs_bin) % 8 > 0:
# 末尾を1で埋める (1-bits pad)
ecs_bin += '1' * (8 - len(ecs_bin) % 8)
# byte stuffing
ecs_hex = ''
for i in range(0, len(ecs_bin), 8):
byte = hex(int(ecs_bin[i: i+8], 2))[2:].upper().zfill(2)
if byte == 'FF':
ecs_hex += 'FF00'
else:
ecs_hex += byte
return ecs_hex
def save(self, result, path):
with JpegBinaryWriter(path) as f:
# SOI
f.write('FFD8')
# DQT
for i, qt in enumerate(self.qt_list):
f.write('FFDB')
f.write(3 + 64, 2)
f.write(i)
f.write(qt.reshape(64)[self.ZIGZAG_ORDER].tolist())
# SOF0
f.write('FFC0')
size = len(self.sampling_rate)
f.write(8 + size * 3, 2)
f.write(8) # bits per pixel per color component
f.write(result['size'][0], 2)
f.write(result['size'][1], 2)
f.write(size)
for i in range(size):
f.write(i+1)
h, v = self.sampling_rate[i]
f.write(h*16 + v) # 4bitずつ
f.write(self.qt_id[i])
# DHT
max_htid = 0
for i in result['huffman_table']['dc'].keys():
if max_htid < i:
max_htid = i
for i in result['huffman_table']['ac'].keys():
if max_htid < i:
max_htid = i
for i in range(max_htid + 1):
if i in result['huffman_table']['dc']:
table = result['huffman_table']['dc'][i]
f.write('FFC4')
f.write(19 + len(table), 2)
f.write(i)
f.write(self.__ht_to_valuelist(table))
if i in result['huffman_table']['ac']:
table = result['huffman_table']['ac'][i]
f.write('FFC4')
f.write(19 + len(table), 2)
f.write(16 + i)
f.write(self.__ht_to_valuelist(table))
# SOS
f.write('FFDA')
size = len(self.ht_id)
f.write(6 + size*2, 2)
f.write(size)
for i, (dc, ac) in enumerate(self.ht_id):
f.write(i + 1)
f.write(dc*16 + ac)
f.write('003F00')
# ECS
f.write(result['ecs'])
# EOI
f.write('FFD9')
@staticmethod
def __ht_to_valuelist(ht):
l = [0] * 16
v = []
for key, value in ht.items():
l[len(value) - 1] += 1
v.append(int(key, 16))
return l + v
class JpegBinaryWriter:
def __init__(self, path):
self.path = path
def __enter__(self):
self.f = open(self.path, 'wb')
return self
def __exit__(self, exc_type, exc_value, traceback):
self.f.close()
def write(self, value, multibyte_size=1, unit_size=4):
if isinstance(value, list):
# 配列の場合は1Byte整数の列として書き込む
self.f.write(bytes(value))
elif isinstance(value, int):
# 整数の場合は1Byteずつの配列に変換して書き込む
self.f.write(bytes(self.__mbint(value, multibyte_size)))
elif isinstance(value, str):
# 文字列の場合は2**unit_size進数文字列として解釈して書き込む
self.f.write(self.__str_to_bytes(value, unit_size=unit_size))
@staticmethod
def __mbint(value, size):
multibyte = []
for i in range(size):
multibyte.append(value % 256)
value //= 256
multibyte.reverse()
return multibyte
@staticmethod
def __str_to_bytes(s, unit_size=4): # 1文字 = 2^unit_size bits
# 16進数文字列を1バイトずつに区切ってbytesに変換
stride = 8 // unit_size
size = len(s)
assert size % stride == 0
decs = []
for i in range(0, size, stride):
decs.append(int(s[i:i+stride], 2**unit_size))
return bytes(decs)
# 確認用
def save_img(path, x, value_range=None):
x = x.astype(np.float64)
if value_range != (0, 255):
if value_range is None:
value_range = (np.min(x), np.max(x))
value_min, value_max = value_range
x = (x - value_min) * 255 / (value_max - value_min)
x = np.floor(x)
x = x.astype(np.uint8)
x = Image.fromarray(x, mode='L')
x.save(path)
if __name__ == '__main__':
from pathlib import Path
input_path = '../image/original.png'
save_dir = '../image/save/'
e = Encoder()
# e = Encoder(quality=90, sampling_rate=((2,2),(1,1),(1,1)))
r = e(input_path)
# 確認用に出力
input_path = Path(input_path)
save_dir = Path(save_dir) / input_path.stem
if not save_dir.exists():
save_dir.mkdir(parents=True)
save_img(str(save_dir / '1_R.png'), r['rgb'][:, :, 0], (0, 255))
save_img(str(save_dir / '1_G.png'), r['rgb'][:, :, 1], (0, 255))
save_img(str(save_dir / '1_B.png'), r['rgb'][:, :, 2], (0, 255))
save_img(str(save_dir / '2_Y.png'), r['ycbcr'][:, :, 0], (-128, 127))
save_img(str(save_dir / '2_Cb.png'), r['ycbcr'][:, :, 1], (-128, 127))
save_img(str(save_dir / '2_Cr.png'), r['ycbcr'][:, :, 2], (-128, 127))
save_img(str(save_dir / '3_Y.png'), r['subsampled'][0], (-128, 127))
save_img(str(save_dir / '3_Cb.png'), r['subsampled'][1], (-128, 127))
save_img(str(save_dir / '3_Cr.png'), r['subsampled'][2], (-128, 127))
for k in range(8):
for l in range(8):
value_max = (1 if k == 0 else np.sqrt(2))*(1 if l == 0 else np.sqrt(2))/8
save_img(str(save_dir / 'DCT_{}_{}.png'.format(k, l)), Encoder.MAT_DCT[k, l], (-value_max, value_max))
save_img(str(save_dir / '4_{}_{}_{}.png'.format(0, 5, 1)), r['blocks'][0][5, 1], (-128, 127))
save_img(str(save_dir / '5_{}_{}_{}.png'.format(0, 5, 1)), r['dct_blocks'][0][5, 1])
save_img(str(save_dir / '5_{}_{}_{}.png'.format(1, 3, 0)), r['dct_blocks'][1][3, 0])
save_img(str(save_dir / '5_{}_{}_{}.png'.format(2, 3, 0)), r['dct_blocks'][2][3, 0])
for i, qt in enumerate(e.QT_BASE):
save_img(str(save_dir / '5_qt_base_{}.png'.format(i)), qt, (1, 128))
for i, qt in enumerate(e.qt_list):
save_img(str(save_dir / '5_qt_{}.png'.format(i)), qt)
save_img(str(save_dir / '6_{}_{}_{}.png'.format(0, 5, 1)), r['quantized_blocks'][0][5, 1])
save_img(str(save_dir / '7_{}_{}.png'.format(0, 5)), r['scanned_blocks'][0][5])
save_img(str(save_dir / '7_{}_{}_{}.png'.format(0, 5, 1)), r['scanned_blocks'][0][5, 1].reshape(1, 64))
save_img(str(save_dir / '7_{}_{}.png'.format(1, 3)), r['scanned_blocks'][1][3])
save_img(str(save_dir / '7_{}_{}.png'.format(2, 3)), r['scanned_blocks'][2][3])
e.save(r, str(save_dir / 'encoded.jpg'))
pass
実行結果
original (比較用)

quality=90, J:a:b=4:4:4の出力例 (32,315 bytes)


quality=90, J:a:b=4:2:0の出力例 (24,249 bytes)


quality=30, J:a:b=4:2:0の出力例 (7,444 bytes)


Yはquality=90, CbCrはquality=19.450, J:a:b=4:2:0の出力例 (20,891 bytes)

