文字コードの話 (4) - UnicodeのEmoji
文字コードについて調べたことをまとめます。
関連記事
- 文字コードの話 (1) - ASCII
- 文字コードの話 (2) - Shift_JIS
- 文字コードの話 (3) - Unicode
- 文字コードの話 (4) - UnicodeのEmoji (本記事)
- Unicode変換ツール
目次
Unicode Emojiの歴史
日本では1997年にJ-PHONEが90種の絵文字を提供したことを皮切りに、携帯電話各社が各々独自の実装でShift_JISを拡張して絵文字を追加して行った。DoCoMoでは(現在はドワンゴ専務取締役の)栗田穣崇氏によって1999年に176種の絵文字が実装され、同じ年にKDDIでも絵文字が実装された。
| 事業者 | Shift_JISでの表現方法 | Unicode 14.0での 採用文字数 |
例 |
|---|---|---|---|
| DoCoMo | 112-114区 | 244字 | 🆖🌕🎠😅🚪 |
| KDDI | 101-104区, 107-110区 | 633字 | 🎹👅💯📛😹 |
| SoftBank | (2Gまで) ISO-2022-JPの呼び出しに似た機能で表現 (3Gから) 109-110区, 113-114区, 117-118区 |
469字 | 🌟🌾🐒💎🕒 |
- KDDIではメール送信にISO-2022-JPを使うとき、送信前に95区以降に配置された文字が85-91区に再配置される(ISO-202-JPでは94区までしか扱えないので)。そのため、NEC選定IBM拡張文字との衝突が発生し、一部の漢字が文字化けを起こす原因となっていた。
- SoftBankでも絵文字の定義領域がIBM拡張文字と被っているので同様の問題が発生していた。
それから日本ではGoogleのGmailやMicrosoftのHotmailが次第に普及し、AppleもiPhoneを発売し始める。Google(・Apple・Microsoft)は日本の携帯メールとの互換性が必要だと考え、こうして2007年から絵文字をUnicodeへ追加するためのオープンソースプロジェクト「emoji4unicode」が始動する。Unicodeへの反映に先立ち、2008年にはGmailで絵文字の対応が始まり、Appleも絵文字に対応したiPhone 3G(iPhone OS 2.2)を発売した。
そして2010年のUnicode 6.0で正式にEmojiという概念が定義される。Unicode 6.0では既にUnicodeに定義されていた139個の符号位置と、新規追加された716個の符号位置をEmojiと定めた(既存のものも含めて図形の総数は1145)。その結果、日本の携帯電話事業者3社で使われていた絵文字はUnicodeに概ね収録されることとなった。
")
その後Emojiは全世界の端末でメールやSNSに利用できるようになり、2010年代に急速に世界中に普及した。
2021年に制定されたUnicode 14.0には3633種類のEmoji図形が登録されている。Emojiの定義前から第0面に元々定義されていたものを除いて、大部分はU+1F000-U+1FAFFの符号位置が割り当てられている。
Emojiの特殊表現
UnicodeのEmojiでは様々な仕組みによってコードポイントを組み合わせて1つの文字(Grapheme cluster)を表現することができる。
異体字セレクタを使うことで白黒のEmojiをカラフルなスタイルに変えたり、逆に色付きのEmojiを白黒に変えたりすることができる。
例: ⚠ + U+FE0F = ⚠️
例: ✨ + U+FE0E = ✨︎Zero Width Joinerを使うことで複数のEmojiを組み合わせた文字を表現することができる。
Unicode 14.0時点でZWJで繋げることで表現可能な文字の数は1352個も存在する。
例: 🐕 + (ZWJ) + 🦺 = 🐕🦺
例: 🧜 + (ZWJ) + ♂ = 🧜♂1桁の数字の後ろにU+20E3を繋げることで囲み数字となる。
例: 7 + U+20E3 = 7⃣多用な肌の色に対応するため、Emoji modifiersという文字(U+1F3FB-U+1F3FF)が用意されている。人に関するEmojiの後ろに繋げることで、対応した肌の色に変化する。
例: 💪 + U+1F3FF = 💪🏿Regional indicator symbolという文字を2つ組み合わせることで様々な国の国旗を表現することができる。
例: 🇯 + 🇵 = 🇯🇵 (環境によっては正しく表示されない)
Emojiに関する逸話・ミーム
英語スラング由来の用法
既存の英語特有のスラング・隠語が、Emojiと結びついて使われるようになった例。
| 字 | 符号位置 | スラングの意味 | 由来 |
|---|---|---|---|
| 🍋 | U+1F34B | 欠陥品 | 果汁を搾り取りやすい性質が、「カモ」「利用されやすい頭の悪い人」のイメージと結び付けられたことから。 |
| 🐐 | U+1F410 | 史上最高 | Greatest of All Timeの略がGOAT(=ヤギ)となることから。 |
| 🥑 | U+1F951 | basic | 流行っていることばかりする人・つまらない人を意味する。 カリフォルニアでアボカドが一時期大流行したことが由来とされる。 |
| 🥜 | U+1F95C | crazy | 「狂気」を意味する「ナットが外れる」(=ネジが外れる)という表現から。 |
| 🧢 | U+1F9E2 | 嘘 | 由来は不明。 一説によると"no lie"を意味するスラング"no cap"から来ているとされる。 |
| 🐍 | U+1F40D | 裏切り者 | (おそらく旧約聖書から来る)英語圏の蛇に対するネガティブなイメージから。 カニエ・ウェストとテイラー・スウィフトの騒動の際にInstagram上で大流行した。 |
Tofu on fire
Emojiは元々日本の携帯電話で使われていた文字であるので、日本特有の文化が強く反映された文字も多く実装されている。👹・👺・💮・🗾・🗻・🏣・🗼・⛩・♨・🎎・🎏・🎐・🎑・🎴・🔰・🎌のように日本文化に関わるものや、🈁・🈂・🈷・🈶のように日本語そのものを含むものがある。
中でもチューリップ型の名札を表すEmoji「📛」(U+1F4DB)は、外国人には炎を連想させたようで炎上や怒りを表す文脈で使われている例が見られたという。そんな中、2014年に絵文字の実物を日本で見つけたというtwitterの投稿に対して、ある人が「Tofu on fire」(燃える豆腐)と表現したことが非常にシュールだとして日本で話題となった。
他にも、「🍢」(U+1F362, おでん)は「ケバブ」、「😪」(U+1F62A, 眠り顔)は「泣き顔」、「💁」(U+1F481, 案内する人)は「生意気な仕草の人」としてもよく使われる。また、"Emoji"という言葉そのものも"Emotion"の"Emo"と関連付けられて認識されている場合があると言われる。
Word of the Year 2015
オックスフォード大学出版局は毎年、その年に話題となった「Word of the Year」(WOTY)を発表しているのだが、2015年のWOTYに選ばれた言葉が「😂」(U+1F602, Face With Tears of Joy, 嬉し泣きの顔)だった。
Oxford Word of the Year 2015 | Oxford Languages
2015年になって「Emoji」という単語の使用頻度が大幅に増加していることがわかり、オックスフォード大学出版局が使用統計を取ったところ、最も使われたEmojiが「😂」であったためこの文字がWOTY選定された。
調査によるとスマートフォンで入力された絵文字の内、イギリスでは20%、アメリカでは17%が「😂」だったという。英語圏では「LOL」と同義の言葉として使われているとされる。
一方で、「😭」(U+1F62D, Loudly Crying Face, 大泣きの顔)も非常に人気があり、2021年のTwitterにおける使用頻度が「😂」を上回っていたらしい。(なお世界3位は「🥺」)
Ninja Cat
Ninja Catは元々Windowsの開発陣の中で流行していたキャラクター。Windows開発者たちのノートパソコンにNinja Catのステッカーが貼られていることにある人が気付いてから次第に外部にもその存在が知られるようになり、2015年にWindows Insider Programの参加者に公開されてからは海外のインターネット上でちょっとしたミームになる。
元々はJason Heuserという人が描いたイラストで、Ninja Catが知られるようになってからはMicrosoftがHeuser氏に許可を取ってNinja CatはWindows 10の(非公式)マスコットとなった。
The origin story of the Microsoft ninjacat - The Old New Thing

その後MicrosoftはNinja Catが象られた6種のEmojiを独自に「Segoe UI Emoji」フォントに実装し、2016年のWindows 10のアップデートによってこれらNinja Catの絵文字が扱えるようになった。Ninja Catの表現にはZero Width Joinerを使う。
- 🐱 + 👤 = 🐱👤
- 🐱 + 🏍 = 🐱🏍
- 🐱 + 💻 = 🐱💻
- 🐱 + 🐉 = 🐱🐉
- 🐱 + 👓 = 🐱👓
- 🐱 + 🚀 = 🐱🚀
しかしその後、2021年にリリースされたWindows 11でNinja CatのEmojiは残念ながら削除されてしまったという。
寿司ビール問題
MySQLではEmojiなどUTF-8で4バイトとなる文字を扱うには「utf8mb4」というcharacter-setを指定する必要がある。しかし、utf8mb4のデフォルトの照合順序「utf8mb4_general_ci」では「🍣」(U+1F363, UTF-8でF0 9F 8D A3)と「🍺」(U+1F37A, UTF-8でF0 9F 8D BA)のEmojiを区別できないという問題が2014年に報告される。つまり、「🍣」でSELECTしようとしたときに「🍺」も返ってくるという問題が発生していた。
この「寿司ビール問題」に対してはMySQL5.6から提供された「utf8mb4_unicode_520_ci」に切り替えることでとりあえず解決する。しかしutf8mb4_unicode_520_ciを使うと今度は「ハ」「バ」「パ」の区別が付かなくなるという別の問題が生じる。
MySQL :: Sushi = Beer ?! An introduction of UTF8 support in MySQL 8.0
この問題を認知したMySQLのサポートは、アクセント記号などによる2段階あるいは3段階のソートが必要になると説明するが、MySQL 5.7以前では1次レベルのソートしか実装されておらず解決手段がないことも指摘している。
その後、2018年にリリースされたMySQL 8.0で日本語に特化した照合順序「utf8mb4_ja_0900_as_cs」が実装されたことで、これらの問題に容易に対応できるようになった。
ハンバーガー絵文字論争
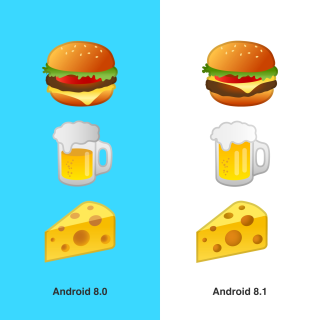
ハンバーガーを表すEmoji「🍔」のGoogle実装について、2017年にあるフリーライターが具材の順番についての違和感を指摘したことを発端とする論争。この指摘に対してGoogleのCEO・Sundar Pichaiが「みんなが納得できる並べ方があれば、全てを投げ打って対応する」と返答したことで話題となる。インターネット上では「どのようなハンバーガーが正解か」「ハンバーガーとはどうあるべきか」という大議論に発展して、各国のニュース番組にも取り上げられることとなった。

問題の内容は、他社の実装ではチーズがパティの上に乗っているのに対して、Googleの実装ではチーズがパティの真下に置かれているというもの。
それから1ヶ月後にリリースされたAndroid8.1のプレビュー版で具材の順が修正され、チーズがパティの真上に乗るよう変更された。そして更に半年後にはGoogleは「Androidの重大なバグ」としてハンバーガーの具材順について謝罪する一幕があった。
またこの修正において、同じく問題点を指摘されていた「グラスの半分しか注がれていないのに泡が溢れているビール」(🍺)のEmojiや、「穴が表面に描かれているだけのように見えるチーズ」(🧀)のEmojiも修正された。
参考
Unicode公式
- Full Emoji List, v14.0
- EmojiSources-6.0.0.txt
- EmojiSources-14.0.0.txt
- UTR #51: Unicode Emoji
- UTR #51: Unicode Emoji
- The Unicode Standard, Vesrion 6.0 Archived Code Charts
携帯電話の文字コード
- au絵文字の文字化け解読リスト - 帰ってきた💫Unicode刑事〔デカ〕リターンズ
- ケータイの文字コードについて調べてみた - 帰ってきた💫Unicode刑事〔デカ〕リターンズ
- SoftBank iPhoneのShift_JISがすごいことになっている件 - 帰ってきた💫Unicode刑事〔デカ〕リターンズ
- 絵文字コード対応表
- Mobile Creation | ソフトバンク
- ソフトバンク絵文字コードの種類と一覧
- 未来情報産業ブログ ソフトバンクの絵文字
歴史
- 📜絵文字とその歴史 | EmojiAll
- 絵文字が開いてしまった「パンドラの箱」第1回--日本の携帯電話キャリアが選んだ道 - CNET Japan
- Correcting the Record on the First Emoji Set
- Emoji
- イジハピ! : 【第1119回】絵文字の多様化
- 「絵文字」は20年でこんなに進化した - iPhone Mania
- Google IMEでWindows 7でもUnicode 6の絵文字を入力する - milk_spoonのブログ
- Top 10 Emoji That Caused Controversies - Listverse