Wordleを強化学習で解く (PyTorch + A2C)
目次
概要
Wordleは、Josh Wardle氏が開発して2021年10月に公開したパズルゲーム。「Mastermind」・「Bulls and Cows」あるいは「ヒットアンドブロー」と呼ばれるパズルの亜種。英単語をテーマにした同様のゲームには「Jotto」や「Lingo」という先例がある。
ゲーム開始時にプレイヤーには見えない状態で 5文字の英単語(正解) が固定され、それに対してプレイヤーは同じく 5文字の英単語(推測) を何度か入力することで最初にゲームが固定した単語を推測する。プレイヤーの入力の各文字位置に対して緑(hit)・黄(blow)・灰(miss)の3種類の判定が行われ、プレイヤーはこの情報をヒントにして単語を絞り込んで行く。
SNSで共有するためにゲーム結果を絵文字で表現する機能が2021年12月に実装されてからTwitterで大流行し、その後2022年1月にはニューヨークタイムズ社がこのパズルを買収したことでも話題となった。
ルール
2022/06/02現在のルール
- 正解となる5文字の英単語は2309単語から選出される。
- 推測で入力することのできる5文字英単語は12974単語。(以下12974=13Kと表す)
- Wordleのページで実行されているスクリプトのソース(main.********.js)にそれぞれの単語リストが記述されている。
- プレイヤーが単語を入力すると、各文字の背景色が変化することでhit・blow・missの判定結果が与えられる。
- 緑(hit): この文字は正解単語のこの位置にある。
- 黄(blow): この文字は正解単語のこの位置にはないが、別の位置にある。
- 灰(miss): この文字は(これ以上)正解単語に含まれない。
- より詳細なルールは後述。
- プレイヤーの試行回数は6回まで。
- 6回以内に正解を当てた場合はその時点でゲーム終了。
- 6回の試行で当てられなかったときもゲーム終了。ゲーム終了時に正解が表示される。
- 正解は毎日0時に更新される。
判定のルール
実際の実装は異なるかもしれないが、以下の方法で生成される結果と同じものがWordleから出力される。
- 推測に含まれる文字を重複なしのリストにして、リスト含まれる各文字cに対して以下を実行。
(例: 推測=ERROR ⇒ {E, O, R})
- 推測内のcの位置を昇順に列挙してLとする。(例: c=R ⇒ L={2, 3, 5})
- 正解に含まれるcの個数を数え上げてnとする。(例: 正解=PARRY, c=R ⇒ n=2)
- Lの各要素iに対して、正解のi文字目がcなら結果のi番目を緑にする。
また、そのときnを1減らしてLからiを除外する。
(例: 正解=PARRY, 推測=ERROR ⇒ i=3が緑, n=1, L={2, 5}) - Lに残った要素について、先頭n要素に対応する結果の位置を黄に、残りを灰にする。
(例: n=1, L={2, 5} ⇒ n=2が黄, n=5が灰)
例

Wordle 341 (2022/05/26)の例。正解はASSET。
1回目の推測TRUTHでは、1文字目のTだけが黄色になって、4文字目のTは灰色になっている。これは正解にTが1文字しか含まれていないからである。このように、入力した文字が正解の別の位置に含まれていたとしても、正解に含まれている個数を超えて発色することはない。
同様に3回目の推測SASSEでは、1文字目のSと3文字目のSだけが発色し、4文字目のSは発色しない。これも正解にSが2個しか含まれていないことによる。
強化学習
Wordleをコンピューターに解かせる手法については、3Blue1Brown氏が機械学習ではなくエントロピー最大化を用いたアルゴリズムで 平均3.421回(多くとも5回)・正答率100% で攻略する方法を確立している。この手法では、2309の正解単語リストの情報を利用している。
強化学習を用いる方法に関しては、Andrew Ho氏がA2C(Advantage Actor-Critic)を用いて、平均3.9回で99.5%の正答率を達成している。(ソースコードは非公開)
この記事ではHoの手法に倣って、A2CでWordleを解くPyTorchプログラムを製作する。既に100%正解できる方法は見つかっているので正解率を競うことが目的ではなく、強化学習+ニューラルネットワークという枠組みの中で試した結果を確認することが目的である。
なお、強化学習やニューラルネットワークという分野そのものの解説はこの記事では取り扱わない。
A2C (Advantage Actor-Critic)
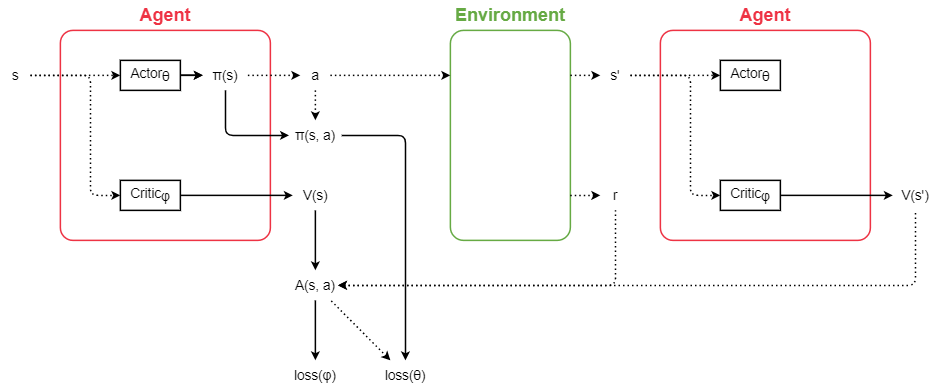
A2C (Advantage Actor-Critic) は強化学習の問題を解くアルゴリズムの一つ。価値関数\( V_\phi(s) \)と方策\( \pi_\theta(s,\cdot) \)の両方をニューラルネットワークで予測し、環境から得られる報酬\(r\)と価値関数そのものを用いて更新していくことで、より多くの報酬が得られるような方策を求めることができる。(\( \phi, \theta \)は重みパラメーター)
状態\(s\)のときに行動\(a\)を取った結果、報酬\(r\)が得られて状態は\(s'\)に遷移したとする。A2Cではこのとき、重みパラメーターを次のように更新する。
\begin{align} \left\{ \begin{array}{ll} A_\phi(s, a) &= r + \gamma V(s') - V_\phi(s), \\ \phi &\leftarrow \phi - \alpha \nabla_\phi A_\phi(s,a)^2, \\ \theta &\leftarrow \theta + \beta A_\phi(s,a) \nabla_\theta \log\left( \pi_\theta(s,a) \right). \\ \end{array} \right. \end{align}
ここで、\(\alpha, \beta\)は学習率で、\(\gamma\)は割引率。いずれもハイパーパラメーターである。
\(A_\phi\)はAdvantageと呼ばれる関数。本来は\(V\)や\(Q\)を使って学習する部分を、\(V\)との差の形である\(A\)を使うことで取りうる値の範囲を狭め、学習を安定化させる効果がある。Aには様々な種類があるが、ここではTD advantage estimateという形式を用いている。
\(V(s')\)には\(V_\phi(s')\)を用いるが、微分の対象にはならない。
下図はA2Cの概略。破線部分は微分が切れていて(計算グラフから切り離されていて)、損失は実戦部分のみを通って逆伝播する。
仕様の詳細
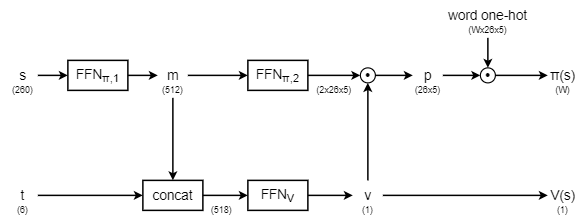
今回の実験では下図のようにモデルを構築した。
後述するように予測の状態\(s\)とターン数\(t\)を分けて入力し、ある程度までターン数によらない特徴量を計算してから途中で統合する形式とした。
その他の細部のテクニックは、Ho氏による既存の手法に倣いつつ詳細を改善して実装した。
状態のベクトル表現
A-Zの各文字種類に対して378通りの状態が起こり得る。既存の手法ではこの状態を16次元(16bit)のベクトルで表現していたが、今回の手法では状態表現の冗長性を改善するために\(5\times 2=10\)次元で各文字種類の状態を表現し、合計\(26\times 10=260\)次元のベクトルをニューラルネットワークへの入力とすることにした。
具体的には、5箇所の位置に対して{hit, blow, miss, 未探索}の4種類の状態しかあり得ないことを利用して、この4種類のステータスを2bitで表現することで合計10次元のベクトルで表現している。なお、実際はblowにも「2個以上あることがわかっている状態」・「丁度1個あることがわかっている場合」・「1個以上であることしかわからない状態」というバリエーションがあるので、この表現で378通り全てを表現しきれているわけではなく、少し情報量が切り捨てられている。
また、この状態ベクトルとは別に、経過ターン数を表す6次元のベクトルもニューラルネットワークの入力に使う。
価値関数や方策はターン経過によらず状態ベクトルのみである程度推測することができると考えられるので、まずは状態ベクトルのみをニューラルネットワークに通してある程度の特徴量を得て、途中から特徴量にターン数ベクトルを統合して更にニューラルネットワークを通して最終的な出力を得ることにした。
one-hotベクトルを使って方策を計算
この実装では、ニューラルネットワークは直接方策\(\pi(s,a)\)を出力するのではなく、\(130=26\times 5\)次元の行列を出力する。この行列は各位置で各文字種類を予測すべき確率に相当している。
この行列に、全単語に対して予め計算された\(13K\times 26\times 5\)次元のone-hotテンソル(各位置における文字のインデックスで1となりそれ以外は0となる)を掛けて内積を取ることで、各予測単語を入力すべき確率\(\pi(s,\cdot)\in (0, 1)^{13K}\)が得られることとなる。
例えば「AHEAD」の場合、one-hot行列は以下のようになる。

このようにモデルを設計することで、ニューラルネットワークの重みが13Kというクラス数に依存しなくなるので、次項のように重みを共有しながら単語数を変化させて学習させるというテクニックが使えるようになる。
単語数を徐々に増やす
ランダムな重みから始めていきなり13Kの単語を扱うのは難しすぎるので、最初は正解も推測も100単語から始める。100単語のWordleで良い結果が出るようになったら段階的に単語数(n_word)を100→1000→2309→13Kと増やして行く。
学習が効率的に進むだけでなく、プログラムのデバッグにも役立つ工夫である。(たった100単語で学習に失敗しているなら、プログラム側にバグがある可能性が高いと判断できる)
recent losses
エージェントが推測に失敗した単語をrecent lossesというキュー(FIFOキュー)に集め、10%の確率でキューから取り出して出題するようにすることで苦手な単語の学習を重点的に行う。
また、キューから出題されたときに限り、5回の推測で失敗した場合は方策を無視して強制的に正解単語を推測するようにする。こうすることで成功体験をエージェントに覚えさせ、苦手な単語を更に克服しやすくしている。
既存の手法ではrecent lossesから出題された場合は必ず正解を強制していたが、今回の手法では1/2で正解を強制して残りの1/2はエージェントに委ねることにした。
実験
学習条件
- 1024個のゲームを同時に実行しながら損失を蓄積し、全てのゲームが終了したら蓄積した損失の平均を取って逆伝播する。逆伝播によってパラメーターを更新したら、次の1024個のゲームを起動してまた学習するという過程の繰り返し。
- 探索はSoftmaxで確率的に行動を選択。
- 報酬設定は、1-4ターンで正解したとき1、5-6ターンで正解したとき0.5、6ターンで正解できなかったとき-10とした。(強化学習は報酬設定に非常に敏感で、報酬設定を少し変えるだけで学習が上手く進まなくなることが今回の実験でも確認された。)
- その他ハイパーパラメーターには学習率\(\alpha=\beta=1.0\times10^{-3}\), 割引率\(\gamma=0.9\)を選択。
- optimizerはAdam(\(\beta_1=0.9, \beta_2=0.999\))。
- 学習にはNVIDIA GeForce GTX 1070 1枚を使用。
- プログラムはPython 3.7.4, PyTorch 1.8.1+cu111で実行。
結果
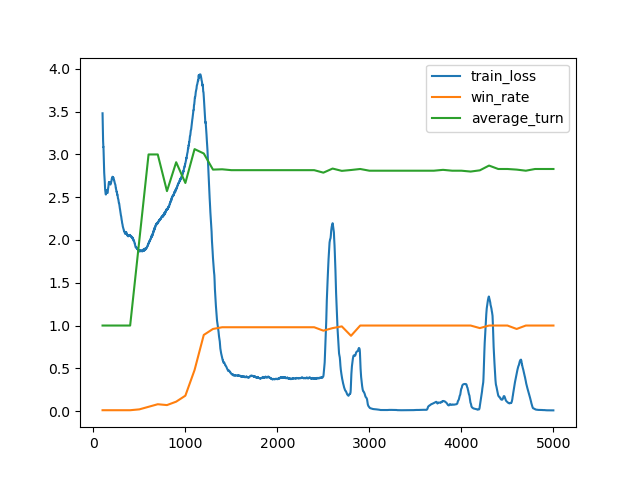
n_word=100
- ランダムに初期化された重みから5000ステップ学習。
- 学習の所要時間は50分。
- 最高勝率は100%、平均ターン数は2.80。(4100 steps)
- 重みの初期値やランダムに選択される100個の単語によってはうまく学習が進まない場合もあったので、そのような場合はやり直した。
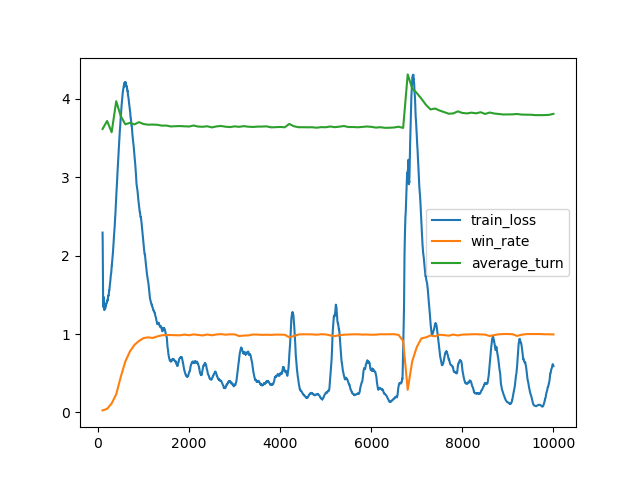
n_word=1000
- n_word=100の最高勝率モデルを読み込んで10000ステップ学習。
- 学習の所要時間は1時間53分。
- 最高勝率は100%、勝利時平均ターン数は3.792。(9600 steps)
n_word=2309
- n_word=1000の最高勝率モデルを読み込んで15000ステップ学習。
- 学習の所要時間は2時間34分。
- 最高勝率は99.65%、勝利時平均ターン数は3.890。(7500 steps)
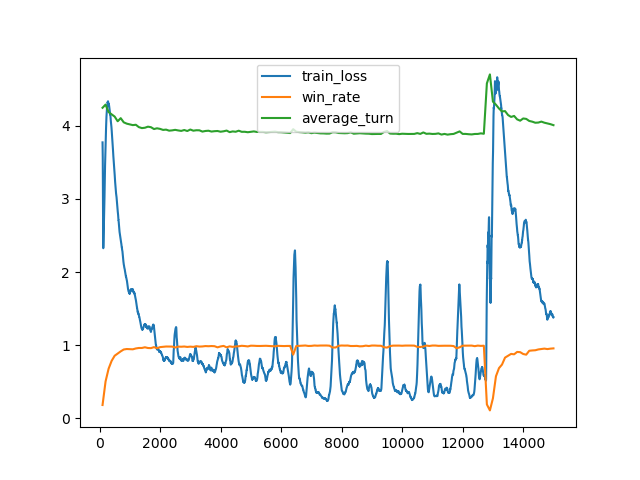
n_word=13K (出題は2309単語から)
- n_word=2309の最高勝率モデルを読み込んで30000ステップ学習。
- この学習のみ同時に起動するゲームの数を2048とした。
- 学習の所要時間は10時間21分。
- 最高勝率は99.78%、勝利時平均ターン数は3.752。(19200 steps)
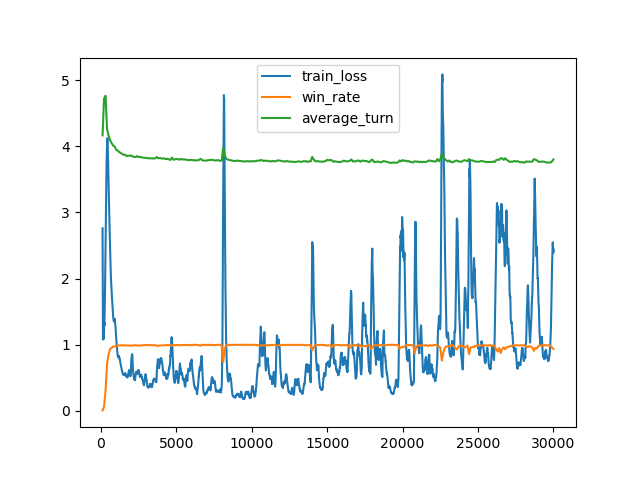
考察
このモデルでは、最初の推測は「SPORT」となった。
「P」を除いて使用頻度の高い文字ばかりで構成されているので、単語を絞り込む目的に対して良い推測になっていると言える。逆に使用頻度がそれほど高くない「P」が入っていることは改善の余地があることを示している。3Blue1Brown氏によると、最善の初手は「SALET」となるらしい。
学習の途中で初手が「QUIRT」や「JERKY」など、効率的ではないと考えられる推測に収束することがあった。そのような現象が確認された場合は、学習を止めて最初からやり直した。
それぞれのターン数で正解できた単語の数は以下の通りで、特に正解できなかった単語は5つ存在した。
- 1回の推測で予測できた単語は1個 (sport)
- 2回の推測で予測できた単語は81個
- 3回の推測で予測できた単語は780個
- 4回の推測で予測できた単語は1103個
- 5回の推測で予測できた単語は305個
- 6回の推測で予測できた単語は34個
- 最後まで正解できなかった単語は5個 (hatch, jaunt, smock, ankle, quash)
正解率・勝利時平均ターン数共に既存のものを上回る結果を得ることができた。
モデル設計には大きな改良の余地がある。
まず、ターン数の情報を1次元の\(V(s)\)に落とし込んでから\(\pi(s)\)に反映している点。この構造は、エージェントが探索するべきか利用するべきか(正解を当てにいくべきか)という方策と、それぞれの場合でその文字を出力するべきかという方策を分離しようという発想から生まれたものだった。しかし、例えば\(V(s)\)が低いときにその要因が序盤に誤った推測をしてしまったからなのか、終盤になって後がないからなのかの区別がついていない可能性があり、探索と利用のバランスを取るために必要な情報は\(V(s)\)だけでは不十分かもしれない。
また、現在はニューラルネットワークが各位置と各文字種類に対する確率(の対数)を出力し、エージェントは単にこれらを掛け合わせて各単語の確率としているがこの構造にも問題がある。この方法は各位置に対する貪欲法になっており、位置同士の相関を完全に無視してしまっている。例えば使用頻度の高い文字で構成される「CRATE」・「TRACE」などの単語は確率が高くなるべきだが、使用頻度の高い文字を複数含む「TEETH」・「STATE」・「CHESS」などの単語は得られるヒントが少なくなるので確率が高くなるべきではない。位置と種類ごとに独立した確率を求める現在のモデルではこのように文字が重複する単語の確率が高くなることを防ぐ手段がない。また、逆にこのような文字が重複した単語を推測したことで負の報酬を得ると、文字の位置と種類の出力が負の方向に評価されてしまうので、本来推測するべき単語が巻き添えを食って過小評価されてしまうことにも繋がる(例えば「STATE」と「CRATE」は最後の3文字が重複しているので、「STATE」でゲームに負けるとその評価が悪影響して「CRATE」の推測確率も低下してしまう)。
3Blue1Brown氏の方法のように、エントロピー項をActor-Criticに追加したSoft Actor-Critic(SAC)という強化学習アルゴリズムも存在する。この方法を取り入れることで、より性能が高いモデルを学習できることが期待される。
ソースコード
以下のディレクトリー構成となるようにして、train.pyを実行すると学習が開始する。demo.pyを実行すると学習済みのモデルをロードしてWordleを解く2種類のデモを実行することができる。
src ├rl │├agent.py │├environment.py │├answer_list.txt │└action_list.txt ├save │└model_best.pth ├train.py └demo.py
学習済みモデル
ここからダウンロード
model_best.pth
単語リスト
学習・推測プログラムを実行するためには、単語リストのファイルを用意する必要がある。単語リストはこのサイトでは配布しないので、各自Wordleのサイトから以下の手順で生成してほしい。
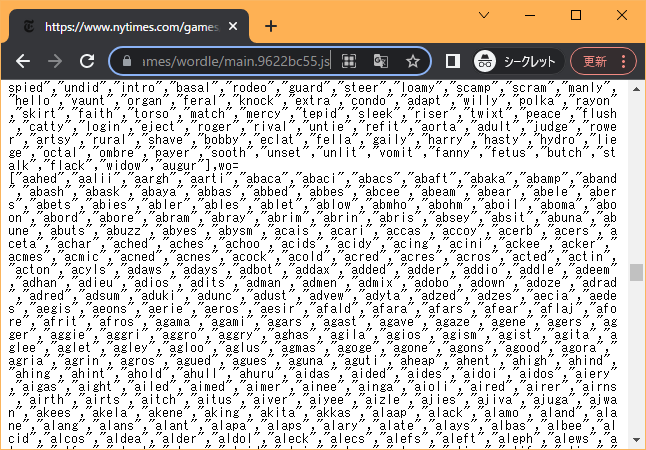
単語リストはWordleのページのソースコードを開き、最後の方に次のように書いてあるjsファイルを開くとその中に記述されている。
<script src="main.********.js"></script>
一見しただけではわかりにくいがリストは2つに分かれていて、前半が正解のリスト、後半が推測のリストになっている。
これらの単語リストを改行区切りのテキストファイルにして、それぞれ「answer_list.txt」・「action_list.txt」という名前でrlディレクトリー内に配置することで、プログラムが単語リストを読み込むことができるようになる。
Pythonコード
environment.py
import random
with open('rl/answer_list.txt') as f:
ANSWER_LIST = f.read().split('\n')
with open('rl/action_list.txt') as f:
ACTION_LIST = ANSWER_LIST + f.read().split('\n')
class WordleGame:
REWARD = [1, 1, 1, 1, 0.5, 0.5, -10]
def __init__(self, answer=None, recent_loss=False):
if isinstance(answer, str):
self.answer = answer
elif isinstance(answer, list):
self.answer = random.choice(answer)
else:
self.answer = random.choice(ANSWER_LIST)
self.recent_loss = recent_loss
# {unexplored, hit, miss}^5 * {blow min, blow max}
# 未探索の位置にその文字がblow min以上blow max以下の数存在することを表す
# blow minが1以上の状態がblowに相当
# 5文字の場合、[0, 5], [1, *], [1, 1], [2, *]の4パターンしか存在しない
self.state = [[0 for _ in range(5)] + [0, 5] for _ in range(26)]
self.turn = 0
self.end = False
# 報酬とゲーム終了状態を返す
def step(self, action):
# 判定
result = self.judge(action)
if result == [3]*5:
self.end = True # stateの更新は行わない
return result, self.REWARD[self.turn], True
elif self.turn >= 5:
self.turn = 6
self.end = True # stateの更新は行わない
return result, self.REWARD[-1], True
else:
self.update_state(action, result) # stateの更新
self.turn += 1
return result, 0, False
def judge(self, action):
if action == self.answer:
return [3]*5
# 0:miss -> black
# 1:blow(right) -> black
# 2:blow(left) -> yellow
# 3:hit -> green
result = [0] * 5
for c in set(action):
idx_list = [i for i, d in enumerate(action) if c == d]
n = self.answer.count(c)
if n > 0:
new_idx_list = []
for i in idx_list:
if self.answer[i] == c:
# hit
result[i] = 3
n -= 1
else:
new_idx_list.append(i)
# blow
for k, i in enumerate(new_idx_list):
result[i] = 2 if k < n else 1
return result
def update_state(self, action, result):
# stateへ反映
for c in set(action):
idx_list = [i for i, d in enumerate(action) if c == d]
c_result = [result[i] for i in idx_list]
c = ord(c) - 97
state = self.state[c]
if 0 in c_result: # miss
self.state[c] = [-1]*5 + [0, 0]
else:
old_blow_min, old_blow_max = state[5:]
blow_min = c_result.count(2) # blow(黄)の個数
if 1 in c_result: # blowの個数が確定している状態
blow_max = blow_min
else:
blow_max = 5 - len(idx_list)
for i, s in enumerate(state[:5]):
if i not in idx_list and s == 1: # 既に正解しているが今回は推測しなかった位置
blow_min -= 1
blow_max -= 1
for i, r in zip(idx_list, c_result):
if state[i] == 0:
# - -> o or - -> xとなった位置
old_blow_min -= 1
old_blow_max -= 1
if r == 3:
state[i] = 1
else: # r == 1 or r == 2
state[i] = -1
state[-2] = max(old_blow_min, blow_min)
state[-1] = min(old_blow_max, blow_max)
# state後処理
need_verify = True
while need_verify:
need_verify = False
# 縦方向
# ある文字に対してoになっている位置は他の文字に対しては必ずxになる
for c, state in enumerate(self.state):
for i in range(5):
if state[i] == 1:
for d, state2 in enumerate(self.state):
if c != d:
state2[i] = -1
# 横方向
for state in self.state:
if state[:5].count(0) > 0:
# blow max == 0なら未探索の位置は全てx
if state[-1] == 0:
for i in [i for i, s in enumerate(state[:5]) if s == 0]:
state[i] = -1
need_verify = True
# blow minと未探索の位置の数が一致するなら未探索の位置は全てo
if state[-2] >= state[:5].count(0):
for i in [i for i, s in enumerate(state[:5]) if s == 0]:
state[i] = 1
need_verify = True
# 不整合の修正
if 0 not in state[:5]:
state[-2] = 0
state[-1] = 0
def __str__(self):
game_str = ['turn:{} of {{0, 1, ... , 6}}'.format(self.turn)]
for i, state in enumerate(self.state):
blowing = state[-2] > 0
state_str = '{}:'.format(chr(i + 97))
for j in range(5):
if state[j] == -1:
symbol = 'x'
elif state[j] == 1:
symbol = 'o'
else:
if blowing:
symbol = '?'
else:
symbol = '-'
state_str += ' ' + symbol
game_str.append(state_str + ': {} {}'.format(state[-2], state[-1]))
return '\n'.join(game_str)
def color_format(action, result):
color_str = []
for c, r in zip(action, result):
if r == 0 or r == 1:
color_str.append('\x1b[48;2;58;58;60m\033[38;2;255;255;255m{}\x1b[0m\x1b[0m'.format(c))
elif r == 2:
color_str.append('\x1b[48;2;181;159;59m\033[38;2;255;255;255m{}\x1b[0m\x1b[0m'.format(c))
elif r == 3:
color_str.append('\x1b[48;2;83;141;78m\033[38;2;255;255;255m{}\x1b[0m\x1b[0m'.format(c))
return ''.join(color_str)
agent.py
import random
import torch
from torch import nn
from torch.nn import functional as F
from rl.environment import ACTION_LIST
class A2CModule(nn.Module):
def __init__(self, action_list=None):
super().__init__()
self.core = A2CModuleCore()
if action_list is None:
self.action_list = ACTION_LIST
else:
self.action_list = action_list
# toメソッドでGPUに自動で移動するように登録している
# state_dictに追加されてしまうので重みを共有するModuleとクラスを分けた
self.register_buffer('word_one_hot', torch.stack([
F.one_hot(torch.LongTensor([ord(c)-97 for c in word]), num_classes=26)
for word in self.action_list]
).to(torch.float32).transpose(1, 2))
def forward(self, s, t):
p, v = self.core(s, t)
p = torch.einsum('bci,wci->bw', p, self.word_one_hot) # Bx13K
p = p.softmax(dim=1)
return p, v
class A2CModuleCore(nn.Module):
def __init__(self):
super().__init__()
self.ffn_policy_1 = nn.Sequential(
nn.Linear(260, 512),
nn.ReLU(),
nn.Dropout(0.05),
nn.Linear(512, 512),
nn.ReLU(),
nn.Dropout(0.05),
nn.Linear(512, 512),
nn.ReLU(),
nn.Dropout(0.05),
)
self.ffn_policy_2 = nn.Sequential(
nn.Linear(512, 512),
nn.ReLU(),
nn.Dropout(0.05),
nn.Linear(512, 512),
nn.ReLU(),
nn.Dropout(0.05),
nn.Linear(512, 260),
)
self.ffn_value = nn.Sequential(
nn.Linear(512 + 6, 128),
nn.ReLU(),
nn.Dropout(0.05),
nn.Linear(128, 32),
nn.ReLU(),
nn.Dropout(0.05),
nn.Linear(32, 1),
)
def forward(self, s, t):
b = s.shape[0]
s = torch.reshape(s, (b, 260)) # Bx260
m = self.ffn_policy_1(s) # Bx512
p = self.ffn_policy_2(m) # Bx260
p = torch.reshape(p, (b, 2, 26, 5)) # Bx2x26x5
v = self.ffn_value(torch.cat([m, t], dim=1)) # Bx1
v2 = torch.cat([v, torch.ones_like(v)], dim=1) # Bx2
p = torch.einsum('bnci,bn->bci', p, v2) # Bx26x5
return p, v
class WordleAgent:
def __init__(self, action_list=None, device=None, model_path=None):
self.model = A2CModule(action_list=action_list)
if model_path is not None:
self.model.core.load_state_dict(torch.load(model_path))
self.device = device
if device is not None:
self.model.to(device)
def get_action(self, state_batch, turn_batch, explore='argmax', force_answer=None):
batch_size = len(state_batch)
# 状態を整形
state_batch_2 = []
for state in state_batch:
state_2 = []
for letter_state in state:
blowing = letter_state[-2] > 0
letter_state_2 = []
for s in letter_state[:5]:
if s == -1:
letter_state_2 += [1, 0]
elif s == 1:
letter_state_2 += [1, 1]
elif blowing:
letter_state_2 += [0, 1]
else:
letter_state_2 += [0, 0]
state_2.append(letter_state_2)
state_batch_2.append(state_2)
state_batch = torch.Tensor(state_batch_2) # Bx26x5
# ニューラルネットワークを通して行動分布と価値観数を得る
turn_batch = F.one_hot(torch.LongTensor(turn_batch), num_classes=6)
if self.device is not None:
state_batch = state_batch.to(self.device)
turn_batch = turn_batch.to(self.device)
p, v = self.model(state_batch, turn_batch) # Bx13K, Bx1
# 行動を決定
if explore.endswith('-softmax'):
epsilon = float(explore.replace('-softmax', ''))
p2 = p * (1 - epsilon) + epsilon/len(self.model.action_list)
p2 = p2.cumsum(dim=1)
p2 /= p2[:, -1].clone().unsqueeze(1)
a = (p2 < torch.rand(batch_size).unsqueeze(1).to(p.device)).sum(dim=1) # Bx13K, Bx1 -> B
elif explore == 'softmax':
p2 = p.cumsum(dim=1)
p2 /= p2[:, -1].clone().unsqueeze(1) # p2[:, -1]は本来1となるはずだが、稀に誤差が発生して1未満になることがあるので補正
a = (p2 < torch.rand(batch_size).unsqueeze(1).to(p.device)).sum(dim=1) # Bx13K, Bx1 -> B
elif explore.endswith('-greedy'):
epsilon = float(explore.replace('-greedy', ''))
a = []
for b in range(batch_size):
if random.random() < epsilon:
a.append(random.randrange(0, len(self.model.action_list)))
else:
a.append(p[b].argmax())
a = torch.Tensor(a).to(p.device)
else: # explore == 'argmax':
a = p.argmax(dim=1)
# エージェントの回答を強制する
if force_answer is not None:
for i, answer in enumerate(force_answer):
if answer is not None and random.random() < 1/2:
a[i] = answer
return a.to(torch.long), p, v.squeeze(1)
train.py
import random
import queue
import pickle
from pathlib import Path
import datetime
import torch
from torch.nn import functional as F
from torch import optim
from rl.environment import ANSWER_LIST, ACTION_LIST, WordleGame, color_format
from rl.agent import WordleAgent
def train(n_word=None, n_iteration=100000, n_worker=10, model_path=None):
save_dir = Path('save') / '{:%Y%m%d_%H%M%S}_n_word={}'.format(datetime.datetime.now(),
n_word if n_word is not None else '13K')
if not save_dir.exists():
save_dir.mkdir(parents=True)
if n_word is None:
answer_list = ANSWER_LIST
action_list = ACTION_LIST
else:
answer_list = random.sample(ANSWER_LIST, n_word)
action_list = answer_list
print(answer_list)
agent = WordleAgent(action_list, device='cuda', model_path=model_path)
gamma = 0.9
optimizer = optim.Adam(agent.model.parameters(), lr=1e-3, betas=(0.9, 0.999))
recent_losses = queue.Queue()
log = {
'train_loss': {
'i': [],
'value': []
},
'win_rate': {
'i': [],
'value': []
},
'average_turn': {
'i': [],
'value': []
},
}
for i in range(n_iteration):
# train
loss = train_step(agent, optimizer, recent_losses, answer_list, action_list, n_worker, gamma=gamma,
console_log=i % 10 == 0)
log['train_loss']['i'].append(i)
log['train_loss']['value'].append(loss)
print('step {} | recent_losses {} | train_loss {}'.format(i, recent_losses.qsize(), loss))
# validate
if (i+1) % 100 == 0:
win_rate, average_turn = validate(agent, answer_list, action_list, n_worker)
log['win_rate']['i'].append(i+1)
log['win_rate']['value'].append(win_rate)
log['average_turn']['i'].append(i+1)
log['average_turn']['value'].append(average_turn)
print('validate {} | win_rate {:.4f} | average_turn {:.2f}'.format(i+1, win_rate, average_turn))
torch.save(agent.model.core.state_dict(),
str(save_dir / 'model_{}_{:.4f}_{:.2f}.pth'.format(i+1, win_rate, average_turn)))
with (save_dir / 'log').open('wb') as f:
pickle.dump(log, f)
def train_step(agent, optimizer, recent_losses, answer_list, action_list, n_worker, gamma=0.9, console_log=False):
agent.model.train()
games = []
for _ in range(n_worker):
if not recent_losses.empty() and random.random() < 0.1:
# FIFOキューから出題
games.append(WordleGame(recent_losses.get(), recent_loss=True))
else:
games.append(WordleGame(answer_list))
actor_batch = []
critic_batch = []
prev_td = None
prev_policy = None
worker_idx = list(range(n_worker))
# console log
if console_log:
print()
if games[0].recent_loss:
print('{} (recent_loss)'.format(games[0].answer))
else:
print(games[0].answer)
print('-----')
while worker_idx:
# s, t -> a, pi(s), V(s)
state_batch, turn_batch, force_answer = get_nn_batch(worker_idx, games, action_list)
w_a, w_ps, w_vs = agent.get_action(
state_batch, turn_batch, explore='softmax', force_answer=force_answer
) # W, Wx13K, W
# a -> r
step_result = [games[idx].step(action_list[a]) for idx, a in zip(worker_idx, w_a)]
# console log
if console_log:
if 0 in worker_idx:
result, _, _ = step_result[worker_idx.index(0)]
print(color_format(action_list[w_a[worker_idx.index(0)]], result))
# ゲームの結果を処理
new_worker_idx = []
w_r = []
end_list = []
for i, (_, r, end) in enumerate(step_result):
w_r.append(r)
end_list.append(end)
if end:
# recent_lossesに単語を追加
game = games[worker_idx[i]]
if game.turn == 6:
recent_losses.put(game.answer)
else:
new_worker_idx.append(worker_idx[i])
worker_idx = new_worker_idx
w_r = torch.Tensor(w_r).to(w_vs.device)
end_list = torch.BoolTensor(end_list).to(w_vs.device)
# 前の状態を使って算出されるloss
if prev_td is not None and prev_policy is not None:
prev_td += gamma * w_vs.detach() # W, W -> W
actor_batch.append(-((prev_policy + 1e-10)/(1 + 1e-10)).log() * prev_td.detach()) # log(0)を防止
critic_batch.append(prev_td ** 2)
td = w_r - w_vs # W, W -> W
policy = w_ps[F.one_hot(w_a, num_classes=w_ps.shape[1]).to(torch.bool)] # Wx13K, W -> W
# 終了したエピソードのloss
actor_batch.append(-((policy[end_list] + 1e-10)/(1 + 1e-10)).log() * td[end_list].detach()) # V(s') == 0
critic_batch.append(td[end_list] ** 2)
# 保持する状態を更新
prev_td = td[end_list.logical_not()]
prev_policy = policy[end_list.logical_not()]
# console log
if console_log:
print()
optimizer.zero_grad()
# これと同じ
# torch.mean(torch.cat(actor_batch)).backward()
# torch.mean(torch.cat(critic_batch)).backward()
loss = torch.mean(torch.cat(actor_batch) + torch.cat(critic_batch))
loss.backward()
optimizer.step()
return loss.item()
@torch.no_grad()
def validate(agent, answer_list, action_list, n_worker):
agent.model.eval()
win_lose_list = []
turn_list = []
for k in range((len(answer_list) - 1) // n_worker + 1):
# answer_listの全ての単語を1回ずつ検査
games = [WordleGame(answer_list[i]) for i in range(k*n_worker, min((k + 1)*n_worker, len(answer_list)))]
worker_idx = list(range(len(games)))
while worker_idx:
# s, t -> a, pi(s), V(s)
state_batch, turn_batch, force_answer = get_nn_batch(worker_idx, games, action_list)
w_a, w_ps, w_vs = agent.get_action(
state_batch, turn_batch
) # W, Wx13K, W
# a -> r
step_result = [games[idx].step(action_list[a]) for idx, a in zip(worker_idx, w_a)]
# ゲームの結果を処理
new_worker_idx = []
for i, (_, r, end) in enumerate(step_result):
if not end:
new_worker_idx.append(worker_idx[i])
worker_idx = new_worker_idx
for game in games:
if game.turn < 6:
win_lose_list.append(1)
turn_list.append(game.turn + 1)
else:
win_lose_list.append(0)
return sum(win_lose_list)/len(win_lose_list), sum(turn_list)/len(turn_list)
def get_nn_batch(worker_idx, games, action_list):
# s, t -> a, pi(s), V(s)
state_batch = []
turn_batch = []
force_answer = []
for idx in worker_idx:
game = games[idx]
state_batch.append(game.state)
turn_batch.append(game.turn)
if game.recent_loss and game.turn == 5:
# recent_lossesから出題されていて最終ターンの場合は、方策を無視して正解する
force_answer.append(action_list.index(game.answer))
else:
force_answer.append(None)
return state_batch, turn_batch, force_answer
if __name__ == '__main__':
# n_word=100
train(n_word=100, n_iteration=5000, n_worker=1024)
# # n_word=1000
# train(n_word=1000, n_iteration=10000, n_worker=1024,
# model_path='save/20220601_200852_n_word=100/model_4100_1.0000_2.80.pth')
# # n_word=2309 (answer_listの全単語)
# train(n_word=2309, n_iteration=15000, n_worker=1024,
# model_path='save/20220601_210250_n_word=1000/model_9600_1.0000_3.79.pth')
# # n_word=None (answer_list, action_listの全単語)
# train(n_word=None, n_iteration=30000, n_worker=2048,
# model_path='save/20220601_225754_n_word=2309/model_7500_0.9965_3.89.pth')
pass
demo.py
import re
import torch
from rl.agent import WordleAgent
from rl.environment import WordleGame, color_format
@torch.no_grad()
def demo1(model_path=None):
agent = WordleAgent(device='cuda', model_path=model_path)
agent.model.eval()
k = 5
game = WordleGame()
while not game.end:
print('turn {}.'.format(game.turn + 1))
# 候補と確率をk個出力
_, p, _ = agent.get_action([game.state], [game.turn])
values, indices = p[0].topk(k)
for rank, (i, v) in enumerate(zip(indices, values)):
print('{}: {}, score={:.6f}'.format(rank+1, agent.model.action_list[i], v.item()))
# input guess
print()
print('Input your guess.')
action = None
while action is None:
action = input('> ')
action = action.lower()
if re.match(r'^[a-z]{5}$', action) is None or action not in agent.model.action_list:
action = None
print('probability of {}: {}'.format(action, p[0, agent.model.action_list.index(action)].item()))
# input result
print()
print('Input the result.')
print('example: 11201 (2:green, 1:yellow, 0:gray)')
result = None
while result is None:
result = input('> ')
if re.match(r'^[012]{5}$', result) is None:
result = None
else:
# resultをupdate_stateの引数として想定する形に加工
new_result = [0]*5
for c in set(action):
idx_list = [i for i, d in enumerate(action) if c == d]
c_result = [result[i] for i in idx_list]
blowing = '1' in c_result or '2' in c_result
for i, r in zip(idx_list, c_result):
if r == '2':
new_result[i] = 3
elif r == '1':
new_result[i] = 2
elif blowing:
new_result[i] = 1
result = new_result
print(color_format(action, result))
game.update_state(action, result)
game.turn += 1
print()
@torch.no_grad()
def demo2(answer=None, model_path=None):
agent = WordleAgent(device='cuda', model_path=model_path)
agent.model.eval()
game = WordleGame(answer)
print(game.answer)
print('-----')
while not game.end:
_, p, _ = agent.get_action([game.state], [game.turn])
action = agent.model.action_list[p[0].argmax()]
result, _, _ = game.step(action)
print(color_format(action, result))
print('-----')
if game.turn == 0:
print('Genius')
if game.turn == 1:
print('Magnificent')
if game.turn == 2:
print('Impressive')
if game.turn == 3:
print('Splendid')
if game.turn == 4:
print('Great')
if game.turn == 5:
print('Phew')
if game.turn == 6:
print(game.answer.upper())
if __name__ == '__main__':
# Wordleを遊ぶプレイヤーにプログラムがアドバイスするデモ
demo1(model_path='save/model_best.pth')
# プレイヤーが出題者となってプログラムにWordleを解かせるデモ
# demo2(model_path='save/model_best.pth') # 指定しない場合は正解がランダムに選択される
# demo2('atoll', model_path='save/model_best.pth')
# demo2('banal', model_path='save/model_best.pth')
# demo2('crimp', model_path='save/model_best.pth')
# demo2('mound', model_path='save/model_best.pth')
# demo2('hunch', model_path='save/model_best.pth')
# demo2('hilly', model_path='save/model_best.pth')
# demo2('match', model_path='save/model_best.pth')