Kullback–Leibler情報量
目次
Kullback–Leibler情報量
同じ確率変数\(x\)に対する2つの異なる確率密度関数\(p(x), q(x)\)について、Kullback–Leibler情報量は次のように定義される。
\begin{align} D_{KL}\left(p\|q\right) := \int p(x) \log \frac{p(x)}{q(x)} dx \end{align}
以後、「KL情報量」と呼ぶ。
KL情報量が非負であることの証明
Jensenの不等式
\(f:R\rightarrow R\)を下に(広義)凸な関数とする。
\begin{align} &\forall\{x_i\}_{i=1}^n\subset R \\ &\forall\{\lambda_i\}_{i=1}^n\subset (0, 1) \quad s.t. \sum_i^n\lambda_i = 1 \end{align}
に対して以下の不等式が成立する。
\begin{align} \sum_i^n \lambda_i f(x_i) \ge f(\sum_i^n \lambda_i x_i) \end{align}
証明
\(f\)が(広義)凸関数であるとは、以下が成立するということ。
\begin{align} &\forall x, y \in R, \forall t \in [0, 1] \\ &tf(x)+(1-t)f(y) \ge f\left( tx+(1-t)y \right) \end{align}
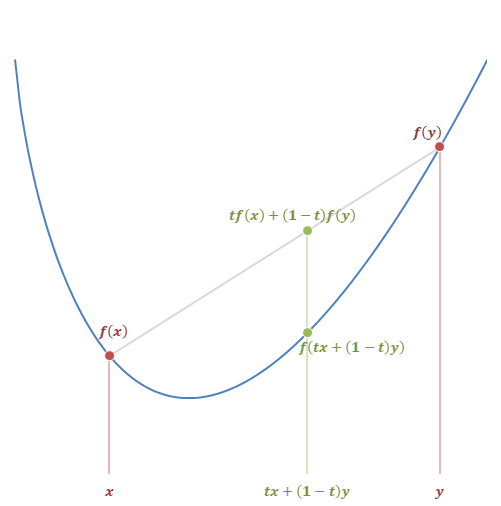
\(n=2\)のときは凸関数の定義そのものなので自明。
\(n = k \ge 3\)のとき、\(n = k-1\)と\(n=2\)のときのJensenの不等式を用いて、
\begin{align} \sum_i^k \lambda_i f(x_i) &= \sum_i^{k-1} \lambda_i f(x_i) + \lambda_k f(x_k) \\ &= \left( \sum_j^{k-1} \lambda_j \right) \left( \sum_i^{k-1} \frac{\lambda_i}{\sum_j^{k-1} \lambda_j} f(x_i) \right) + \lambda_k f(x_k) \\ &\ge \left( \sum_j^{k-1} \lambda_j \right) f\left(\sum_i^{k-1} \frac{\lambda_i}{\sum_j^{k-1} \lambda_j} x_i\right) + \lambda_k f(x_k) \\ &= \left( 1-\lambda_k \right) f\left(\sum_i^{k-1} \frac{\lambda_i}{1-\lambda_k} x_i\right) + \lambda_k f(x_k) \\ &\ge f\left((1-\lambda_k)\sum_i^{k-1} \frac{\lambda_i}{1-\lambda_k} x_i + \lambda_k x_k\right) \\ &= f\left(\sum_i^{k-1} \lambda_i x_i + \lambda_k x_k\right) \\ &= f\left(\sum_i^{k} \lambda_i x_i\right) \\ \end{align}
なお、\(f\)が狭義凸関数であるとき、等式が成立する必要十分条件は以下。
\begin{align} x_i = x_j \quad \forall i, j \end{align}
対数和不等式
\begin{align} &\forall \{a_i\}_i^n, \forall\{b_i\}_i^n \subset R_{+} \\ &\sum_i a_i \log \frac{a_i}{b_i} \ge \left( \sum_i a_i \right) \log \frac{\sum_i a_i}{\sum_i b_i} \end{align}
証明
\(f(x) := x\log(x) \quad x \in (0,\infty)\)とすると、
\begin{align} \left(\frac{d}{dx}\right)^2 f(x)=1/x>0 \quad (\forall x\in(0,\infty)) \end{align}
なので、\(f\)は(狭義)凸関数。
\(x_i, \lambda_i\)を次のように定義する。
\begin{align} \begin{cases} x_i := \frac{a_i}{b_i} \\ \lambda_i := \frac{b_i}{\sum b_j} \end{cases} \end{align}
これらに対してJensenの不等式を適用。
\begin{align} \sum_i a_i \log \frac{a_i}{b_i} &= \left(\sum b_j\right)\sum \frac{b_i}{\sum b_j}\frac{a_i}{b_i} \log \frac{a_i}{b_i}\\ &= \left(\sum b_j\right)\sum \lambda_i x_i \log x_i \\ &= \left(\sum b_j\right)\sum \lambda_i f(x_i) \\ &\ge \left(\sum b_j\right)f\left(\sum \lambda_i x_i\right) \\ &= \left(\sum b_j\right)f\left(\sum \frac{a_i}{\sum b_j}\right) \\ &= \left(\sum b_i\right)f\left(\frac{\sum a_i}{\sum b_i}\right) \\ &= \left(\sum b_i\right)\frac{\sum a_i}{\sum b_i} \log \frac{\sum a_i}{\sum b_i} \\ &= \left( \sum_i a_i \right) \log \frac{\sum_i a_i}{\sum_i b_i} \end{align}
fは狭義凸関数なので、等号が成立する必要十分条件は以下。
\begin{align} \frac{a_i}{b_i} = \frac{a_j}{b_j} \quad \forall i, j \end{align}
つまり、
\begin{align} \exists C\in(0,\infty) s.t. b_i = C a_i \quad \forall i \end{align}
特に、\(\sum a_i = \sum b_i\)のとき、等号が成立する必要十分条件は、
\begin{align} b_i = a_i \quad \forall i \end{align}
KL情報量への適用
\begin{align} \begin{cases} a_i = p_i \quad s.t. \sum p_i = 1 \\ b_i = q_i \quad s.t. \sum q_i = 1 \end{cases} \end{align}
として、対数和不等式を適用すると、
\begin{align} \sum p_i \log \frac{p_i}{q_i} &\ge \left(\sum p_i\right) \log \frac{\sum p_i}{\sum q_i} \\ &= 1 \log\frac{1}{1} \\ &= 0 \end{align}
(\(p, q\)の積分可能性についての条件が満たされるとき、)この関係を積分に拡張することで、KL情報量の非負性を示すことができる。
\begin{align} D_{KL}\left(p\|q\right) &= \int p(x) \log \frac{p(x)}{q(x)} dx \\ &\ge \left(\int p(x)dx\right) \log \frac{\int p(x)dx}{\int q(x)dx} \\ &= 1 \log\frac{1}{1} \\ &= 0 \end{align}
最小値の達成条件
\(p\)と\(q\)が一致するとき\(\log p(x)/q(x) = 0\)となるので、KL情報量は最小値0を達成する。
また、最小値0を達成するとき、
\begin{align} p(x) = q(x) \quad a.e. \end{align}
となることがわかっている。
\(D_{KL}\left(p|q\right)\)には\(p\)と\(q\)の対称性がないので、KL情報量は距離関数にはならないが、
\begin{align} \begin{cases} D_{KL}\left(p\|q\right) \ge 0 \\ D_{KL}\left(p\|q\right) = 0 \Leftrightarrow p = q \quad a.e. \end{cases} \end{align}
という性質を満たすことから、距離に準ずる概念として利用されることがある。
正規分布同士のKL情報量
N次元正規分布同士のKL情報量を計算する。
\begin{align} p(x) = p_\mathcal{N}(x | \mu_p, \Sigma_p) = \frac{1}{(2\pi)^{N/2}|\Sigma_p|^{1/2}} \exp \left(-\frac{1}{2}(x-\mu_p)^\top\Sigma_p^{-1}(x-\mu_p)\right) \\ q(x) = q_\mathcal{N}(x | \mu_q, \Sigma_q) = \frac{1}{(2\pi)^{N/2}|\Sigma_q|^{1/2}} \exp \left(-\frac{1}{2}(x-\mu_q)^\top\Sigma_q^{-1}(x-\mu_q)\right) \\ \end{align}
とする。
\begin{align} D_{KL}\left(p\|q\right) &= \int p(x) \log \frac{p(x)}{q(x)} dx \\ &= \int p(x) \left(\log p(x) - \log q(x)\right) dx \\ &= \int p(x) \frac{1}{2} \left(-N\log\left(2\pi\right) - \log |\Sigma_p| - (x-\mu_p)^\top\Sigma_p^{-1}(x-\mu_p) + N\log\left(2\pi\right) + \log |\Sigma_q| + (x-\mu_q)^\top\Sigma_q^{-1}(x-\mu_q) \right) dx \\ &= \int p(x) \frac{1}{2} \left(\log \frac{|\Sigma_q|}{|\Sigma_p|} - (x-\mu_p)^\top\Sigma_p^{-1}(x-\mu_p) + (x-\mu_q)^\top\Sigma_q^{-1}(x-\mu_q) \right) dx \\ &= \frac{1}{2}\left( \log \frac{|\Sigma_q|}{|\Sigma_p|} - \int p(x)(x-\mu_p)^\top\Sigma_p^{-1}(x-\mu_p)dx + \int p(x)(x-\mu_q)^\top\Sigma_q^{-1}(x-\mu_q)dx \right) \\ \end{align}
ここで、トレースの可換性を用いる。
\begin{align} tr(AB) = tr(BA) \end{align}
\(x^\top A x\)は\(1\times 1\)行列と見ることができるので、
\begin{align} x^\top A x &= tr(x^\top A x) \\ &= tr(Axx^\top) \\ \end{align}
が成立する。これを利用すると各項は次のようになる。
\begin{align} &\int p(x)(x-\mu_p)^\top\Sigma_p^{-1}(x-\mu_p)dx \\ &= \int p(x)tr\left(\Sigma_p^{-1}(x-\mu_p)(x-\mu_p)^\top\right)dx \\ &= tr\left(\Sigma_p^{-1}\int p(x)(x-\mu_p)(x-\mu_p)^\top dx\right) \\ &= tr\left(\Sigma_p^{-1}\Sigma_p\right) \\ &= tr\left(I\right) \\ &= N \\ \\ &\int p(x)(x-\mu_q)^\top\Sigma_q^{-1}(x-\mu_q)dx \\ &= \int p(x)tr\left(\Sigma_q^{-1}(x-\mu_q)(x-\mu_q)^\top\right)dx \\ &= tr\left(\Sigma_q^{-1}\int p(x)(x-\mu_q)(x-\mu_q)^\top dx\right) \\ &= tr\left(\Sigma_q^{-1}\int p(x)(x-\mu_p+\mu_p-\mu_q)(x-\mu_p+\mu_p-\mu_q)^\top dx\right) \\ &= tr\left(\Sigma_q^{-1}\int p(x)\left((x-\mu_p)(x-\mu_p)^\top+(x-\mu_p)(\mu_p-\mu_q)^\top+(\mu_p-\mu_q)(x-\mu_p)^\top+(\mu_p-\mu_q)(\mu_p-\mu_q)^\top\right) dx\right) \\ &= tr\left(\Sigma_q^{-1}\left(\Sigma_p + 0 + 0 + (\mu_p-\mu_q)(\mu_p-\mu_q)^\top \right) \right) \\ &= tr\left(\Sigma_q^{-1}\Sigma_p\right) + tr\left(\Sigma_q^{-1}(\mu_p-\mu_q)(\mu_p-\mu_q)^\top\right) \\ &= tr\left(\Sigma_q^{-1}\Sigma_p\right) + (\mu_p-\mu_q)^\top\Sigma_q^{-1}(\mu_p-\mu_q) \\ \end{align}
よって、正規分布同士のKL情報量は以下のようになる。
\begin{align} D_{KL}\left(p\|q\right) &= \frac{1}{2}\left( \log \frac{|\Sigma_q|}{|\Sigma_p|} - \int p(x)(x-\mu_p)^\top\Sigma_p^{-1}(x-\mu_p)dx + \int p(x)(x-\mu_q)^\top\Sigma_q^{-1}(x-\mu_q)dx \right) \\ &= \frac{1}{2}\left( \log \frac{|\Sigma_q|}{|\Sigma_p|} - N + tr\left(\Sigma_q^{-1}\Sigma_p\right) + (\mu_p-\mu_q)^\top\Sigma_q^{-1}(\mu_p-\mu_q) \right) \\ \end{align}
\begin{align} p(x) = p_\mathcal{N}(x | \mu_p, \Sigma_p) = \frac{1}{(2\pi)^{N/2}|\Sigma_p|^{1/2}} \exp \left(-\frac{1}{2}(x-\mu_p)^\top\Sigma_p^{-1}(x-\mu_p)\right) \\ q(x) = q_\mathcal{N}(x | \mu_q, \Sigma_q) = \frac{1}{(2\pi)^{N/2}|\Sigma_q|^{1/2}} \exp \left(-\frac{1}{2}(x-\mu_q)^\top\Sigma_q^{-1}(x-\mu_q)\right) \\ \end{align}
のとき、
\begin{align} D_{KL}\left(p\|q\right) = \frac{1}{2}\left( \log \frac{|\Sigma_q|}{|\Sigma_p|} - N + tr\left(\Sigma_q^{-1}\Sigma_p\right) + (\mu_p-\mu_q)^\top\Sigma_q^{-1}(\mu_p-\mu_q) \right) \\ \end{align}
特に、\(\Sigma_q, \Sigma_p\)が対角行列のときは以下のようにも表現できる。
\begin{align} D_{KL}\left(p\|q\right) &= \frac{1}{2}\left( \log \frac{|\Sigma_q|}{|\Sigma_p|} - N + tr\left(\Sigma_q^{-1}\Sigma_p\right) + (\mu_p-\mu_q)^\top\Sigma_q^{-1}(\mu_p-\mu_q) \right) \\ &= \frac{1}{2}\left( \log \frac{\prod_i \Sigma_{q,ii}}{\prod_i \Sigma_{p,ii}} - N + \sum_i \frac{\Sigma_{p,ii}}{\Sigma_{q,ii}} + \sum_i \frac{(\mu_{p,i}-\mu_{q,i})^2}{\Sigma_{q,ii}} \right) \\ &= \frac{1}{2}\sum_i \left( \log \frac{\Sigma_{q,ii}}{\Sigma_{p,ii}} - 1 + \frac{\Sigma_{p,ii}}{\Sigma_{q,ii}} + \frac{(\mu_{p,i}-\mu_{q,i})^2}{\Sigma_{q,ii}} \right) \\ &= \frac{1}{2}\sum_i \left( \frac{(\mu_{p,i}-\mu_{q,i})^2}{\Sigma_{q,ii}} - \log \frac{\Sigma_{p,ii}}{\Sigma_{q,ii}} + \frac{\Sigma_{p,ii}}{\Sigma_{q,ii}} - 1 \right) \\ \end{align}