6種類の記号だけで記述するJavaScriptの特殊記法
目次
JSFuck
JSFuckは、JavaScriptのコードを[]()!+の6種類の文字だけで記述する記法で、2010年に考案された。名称や発想は、8種類の文字だけで記述するプログラミング言語Brainfuckに由来する。
6種類の文字の組み合わせによって、数値・文字列・関数などを生成し、最終的に任意のJavaScriptコードを実行できるようになる。
可読性は低く、コードサイズも膨大になり、処理も冗長になるので、実用性はほとんどない。単なる遊びやパズルとして楽しまれるものである。
本稿の内容は次の環境で検証した。
- Webブラウザー: Google Chrome 136.0.7103.114
- JSエンジン: V8 13.6.233.10
各記号の機能
まずは、各記号でできることを確認する。
[] : 配列リテラル・配列やObjectの要素にアクセス
[]では配列を作ることができる。
[2, 3, 5, 7, 11]
また、配列・Object・文字列の要素を取得することができる。
[2, 3, 5, 7, 11][3] // 7
({
a: 13,
b: 17
})['b'] // 17
'apple'[3] // 'l'
() : 式のグループ化・関数の呼び出し
()では式をグループ化することができる。
例えば、次のように演算の優先順位を変えることができる。
2 * 3 + 5 // 11 2 * (3 + 5) // 16 2 * [3 + 5][0] // 16: The same can be done with [] instead of ().
また、関数の呼び出しにも()を利用する。
typeof(19) // 'number'
new Object() // {}
+ : 単項プラス演算子・加算演算子
単項プラス演算子
式の先頭に+を付与することで、Number型に変換することができる。つまり、+xはNumber(x)と同義。
このように使う+を単項プラス演算子と言う。
+undefined // NaN +null // 0 +true // 1 +false // 0 +'' // 0 +'23' // 23 +'1e4' // 10000 +'a' // NaN
非プリミティブ値に対して単項プラスを実行すると、Number(x.toString())と同じ結果が得られる。(ただし、クラスにvalueOf()関数が定義されている場合はそちらが優先される)
toString()が定義されていないObjectでtoString()を実行すると、Object.prototype.toStringに従って'[object Object]'が返ってくるので、単項プラスの結果はNaNになる。
+{} // NaN
({}).toString() // '[object Object]'
Number('[object Object]') // NaN
配列のtoString()は、各要素に対してtoString()を実行した結果を,で結合した文字列が返ってくるように定義されている。(要素がない場合は空文字)
したがって配列に対する単項プラスの結果は次のようになる。
- 空の配列の場合: 0
- 要素が1つだけの配列の場合: その要素をStringに変換してからNumberに変換した値
- 要素が2つ以上の配列の場合: NaN
+[] // 0
[].toString() // ''
Number('') // 0
+[29] // 29
[29].toString() // '29'
Number('29') // 29
+[31, 37] // NaN
[31, 37].toString() // '31' + ',' + '37' = '31,37'
Number('31,37') // NaN
+['41'] // 41
['41'].toString() // '41'
Number('41') // 41
加算
また、+では式同士の加算を行うこともできる。
+の左右の項がプリミティブ値なら、Numberに変換してから加算を行う。
43 + 47 // 90 Infinity + 1 // Infinity NaN + 1 // NaN undefined + 1 // NaN + 1 = NaN null + 1 // 0 + 1 = 1 true + 1 // 1 + 1 = 2 false + 1 // 0 + 1 = 1
+の左右の項がプリミティブ値とStringなら、左右両方をtoString()で文字列に変換してから文字列の結合を行う。
'53' + '53' // '5359' 61 + '67' // '6167' undefined + '' // 'undefined' null + '' // 'null' true + '' // 'true' false + '' // 'false'
+の左右の項が一般のObjectの場合は、toString()で文字列に変換する。その後、+の左右のどちらかがStringの場合と同様に文字列の結合が行われる。
(ただし、ObjectにvalueOf()関数が定義されている場合はそちらが優先されてtoString()は実行されず、その後はvalueOf()が返した値に従って数値の加算か文字列の結合が行われる)
[] + 1 // '1'
[].toString() // ''
'' + 1 // '1'
({}) + 1 // '[object Object]1'
({}).toString() // '[object Object]'
'[object Object]' + 1 // '[object Object]1'
! : 論理否定演算子
!ではBooleanの反転を行うことができる。
!true // false !false // true
Boolean以外の型の値については、truthyな値はtrueとして、falsyな値はfalseとして扱われ、論理否定が行われる。
falsyな値はfalse, undefined, null, 0, -0, NaN, 0n, '', document.allの9種類。それ以外の全ての値がtruthyな値と定められている。
!undefined // true
!null // true
!0 // true
!-0 // true
!NaN // true
!0n // true
!'' // true
!document.all // true
!71 // false
!'false' // false
![] // false
!{} // false
基本的な値の作成
[]()!+の6種類の文字で作ることのできる値を考える。
基本となる値は空の配列[]で、その値を演算によって変化させていく。
空の配列・数値・Boolean・undefined
既に確認した演算の性質を用いて、次のようにBooleanと数値を得ることができる。
[] // [] ![] // false !![] // true
+[] // 0 +!![] // +true = 1 !![]+!![] // true+true = 2 !![]+!![]+!![] // 3 !![]+!![]+!![]+!![] // 4 !![]+!![]+!![]+!![]+!![] // 5 !![]+!![]+!![]+!![]+!![]+!![] // 6 !![]+!![]+!![]+!![]+!![]+!![]+!![] // 7 !![]+!![]+!![]+!![]+!![]+!![]+!![]+!![] // 8 !![]+!![]+!![]+!![]+!![]+!![]+!![]+!![]+!![] // 9 +!![]+[+[]] // 1+[0] = 1+'0' = '10' +!![]+[+!![]] // 1+[1] = 1+'1' = '11' +!![]+[!![]+!![]] // '12' !![]+!![]+[+[]] // 1+[0] = 1+'0' = '20' !![]+!![]+!![]+[+[]] // 1+[0] = 1+'0' = '30' !![]+!![]+!![]+!![]+[+[]] // 1+[0] = 1+'0' = '40'
配列の存在しない要素にアクセスしようとするとundefinedが得られる。最短のコードは以下。
[][[]] // [][[].toString()] = [][""] = undefined
また、[false]を数値に変換しようとするとNaNになる。
+[![]] // +[false] = +'false' = NaN
文字 (基本)
既に得られた値に対して、[]+xを実行することでxを文字列に変換することができる。これは、[].toString()が空文字になるという性質を利用したものであり、[]+xは''+xと同義になる。
[]+![] // []+false = 'false' []+!![] // []+true = 'true' []+[][[]] // []+undefined = 'undefined' +[][[]]+[] // NaN+[] = 'NaN'
これらの文字列の要素にアクセスすることで、各文字を取り出すことができる。
([]+![])[+[]] // 'false'[0] = 'f' ([]+![])[+!![]] // 'false'[1] = 'a' ([]+![])[!![]+!![]] // 'false'[2] = 'l' ([]+![])[!![]+!![]+!![]] // 'false'[3] = 's' ([]+![])[!![]+!![]+!![]+!![]] // 'false'[4] = 'e'
([]+!![])[+[]] // 'true'[0] = 't' ([]+!![])[+!![]] // 'true'[1] = 'r' ([]+!![])[!![]+!![]] // 'true'[2] = 'u' ([]+!![])[!![]+!![]+!![]] // 'true'[2] = 'e'
([]+[][[]])[+[]] // 'undefined'[0] = 'u' ([]+[][[]])[+!![]] // 'undefined'[1] = 'n' ([]+[][[]])[!![]+!![]] // 'undefined'[2] = 'd' ([]+[][[]])[!![]+!![]+!![]] // 'undefined'[3] = 'e' ([]+[][[]])[!![]+!![]+!![]+!![]] // 'undefined'[4] = 'f' ([]+[][[]])[!![]+!![]+!![]+!![]+!![]] // 'undefined'[5] = 'i' ([]+[][[]])[!![]+!![]+!![]+!![]+!![]+!![]] // 'undefined'[6] = 'n' ([]+[][[]])[!![]+!![]+!![]+!![]+!![]+!![]+!![]] // 'undefined'[7] = 'e' ([]+[][[]])[!![]+!![]+!![]+!![]+!![]+!![]+!![]+!![]] // 'undefined'[8] = 'd'
(+[![]]+[])[+[]] // 'NaN'[0] = 'N' (+[![]]+[])[+!![]] // 'NaN'[1] = 'a' (+[![]]+[])[!![]+!![]] // 'NaN'[2] = 'N'
ここで、例えば'i'はundefinedの5番目の要素として取り出しているが、添字の5を表現するのに24文字使うので、'i'全体では37文字も必要になる。そこで、先頭に'false'の5文字を追加して'falseundefined'の10番目を取得するようにすれば、次のように27文字に短縮することができる。
([![]]+[][[]])[+!![]+[+[]]] // ([false]+undefined)['10'] = 'falseundefined'['10'] = 'i'
これらをまとめると、それぞれの最短の表現は次のようになる。
| 文字 | コード | コードの意味 | 文字数 |
|---|---|---|---|
| a | ([]+![])[+!![]] | 'false'[1] | 15 |
| d | ([]+[][[]])[!![]+!![]] | 'undefined'[2] | 22 |
| e | ([]+!![])[!![]+!![]+!![]] | 'true'[2] | 25 |
| f | ([]+![])[+[]] | 'false'[0] | 13 |
| i | ([![]]+[][[]])[+!![]+[+[]]] | ([false]+undefined)['10'] | 27 |
| l | ([]+![])[!![]+!![]] | 'false'[2] | 19 |
| n | ([]+[][[]])[+!![]] | 'undefined'[1] | 18 |
| r | ([]+!![])[+!![]] | 'true'[1] | 16 |
| s | ([]+![])[!![]+!![]+!![]] | 'false'[3] | 24 |
| t | ([]+!![])[+[]] | 'true'[0] | 14 |
| u | ([]+[][[]])[+[]] | 'undefined'[0] | 16 |
| N | (+[![]]+[])[+[]] | 'NaN'[0] | 16 |
'e'を使うことで、数値の指数表記が可能になる。
'1e100'を数値に変換すると1e+100になることから、'+'が得られる。
'11e20'を数値に変換すると1.1e+21になることから、'.'が得られる。
'1e1000'を数値に変換するとInfinityになることから、'I'と'y'が得られる。
+(+!![]+([]+!![])[!![]+!![]+!![]]+[+!![]]+[+[]]+[+[]]) // +'1e100' = 1e+100 (+(+!![]+([]+!![])[!![]+!![]+!![]]+[+!![]]+[+[]]+[+[]])+[])[!![]+!![]] // (1e+100 + [])[2] = '+' +(+!![]+[+!![]]+([]+!![])[!![]+!![]+!![]]+[!![]+!![]]+[+[]]) // +'11e20' = 1.1e+21 (+(+!![]+[+!![]]+([]+!![])[!![]+!![]+!![]]+[!![]+!![]]+[+[]])+[])[+!![]] // (1.1e+21 + [])[1] = '.' +(+!![]+([]+!![])[!![]+!![]+!![]]+[+!![]]+[+[]]+[+[]]+[+[]]) // +'1e1000' = Infinity (+(+!![]+([]+!![])[!![]+!![]+!![]]+[+!![]]+[+[]]+[+[]]+[+[]])+[])[+[]] // (Infinity+[])[0] = 'I' (+[![]]+[+[+!![]+([]+!![])[!![]+!![]+!![]]+[+!![]]+[+[]]+[+[]]+[+[]]]])[+!![]+[+[]]] // (NaN+[Infinity])[10] = 'y'
| 文字 | コードの意味 | 文字数 |
|---|---|---|
| y | (Infinity+[])[0] | 70 |
| I | (NaN+[Infinity])[10] | 84 |
| + | (1e+100 + [])[2] | 70 |
| . | (1.1e+21 + [])[1] | 72 |
関数
ここまでの手順で、一部の文字を利用できるようになった。
今度は、これらを用いて組み込みオブジェクトのprototypeに定義されている関数にアクセスすることを試みる。
at関数
これまでに登場したNumber, Boolean, String, Arrayで使える関数は次のように調べられる。
Object.getOwnPropertyNames(Boolean.prototype) // ['constructor', 'toString', 'valueOf'] Object.getOwnPropertyNames(Number.prototype) // ['constructor', 'toExponential', 'toFixed', 'toPrecision', 'toString', 'valueOf', 'toLocaleString'] Object.getOwnPropertyNames(String.prototype) // ['length', 'constructor', 'anchor', 'at', 'big', 'blink', 'bold', 'charAt', 'charCodeAt', 'codePointAt', 'concat', 'endsWith', 'fontcolor', 'fontsize', 'fixed', 'includes', 'indexOf', 'isWellFormed', 'italics', 'lastIndexOf', 'link', 'localeCompare', 'match', 'matchAll', 'normalize', 'padEnd', 'padStart', 'repeat', 'replace', 'replaceAll', 'search', 'slice', 'small', 'split', 'strike', 'sub', 'substr', 'substring', 'sup', 'startsWith', 'toString', 'toWellFormed', 'trim', 'trimStart', 'trimLeft', 'trimEnd', 'trimRight', 'toLocaleLowerCase', 'toLocaleUpperCase', 'toLowerCase', 'toUpperCase', 'valueOf'] Object.getOwnPropertyNames(Array.prototype) // ['length', 'constructor', 'at', 'concat', 'copyWithin', 'fill', 'find', 'findIndex', 'findLast', 'findLastIndex', 'lastIndexOf', 'pop', 'push', 'reverse', 'shift', 'unshift', 'slice', 'sort', 'splice', 'includes', 'indexOf', 'join', 'keys', 'entries', 'values', 'forEach', 'filter', 'flat', 'flatMap', 'map', 'every', 'some', 'reduce', 'reduceRight', 'toReversed', 'toSorted', 'toSpliced', 'with', 'toLocaleString', 'toString']
この中で、Array.prototype.atは'a'と't'さえあればアクセスでき、しかも必要な文字数が少ない。次のように取得することができる。
[][([]+![])[+!![]]+([]+!![])[+[]]] // []['at'] = Array.prototype.at
これを文字列にすると次のようになる。(JSエンジンによって動作が異なる)
[]+[][([]+![])[+!![]]+([]+!![])[+[]]] // []+[]['at'] = 'function at() { [native code] }'
この文字列から'c'・'o'・'('・')'・' 'を取得することができる。('{'・'}'も取得できるが、そのインデックスはJSエンジンによって異なる)
([]+[][([]+![])[+!![]]+([]+!![])[+[]]])[!![]+!![]+!![]] // ([]+[]['at'])[3] = 'c'
([!![]]+[][([]+![])[+!![]]+([]+!![])[+[]]])[+!![]+[+[]]] // ([true]+[]['at'])['10'] = 'o'
([]+[][([]+![])[+!![]]+([]+!![])[+[]]])[+!![]+[+!![]]] // ([]+[]['at'])['11'] = '('
([]+[][([]+![])[+!![]]+([]+!![])[+[]]])[+!![]+[!![]+!![]]] // ([]+[]['at'])['12'] = ')'
(+[]+[+[]]+[][([]+![])[+!![]]+([]+!![])[+[]]])[+!![]+[+[]]] // (0+[0]+[]['at'])['10'] = ' '
| 文字 | コード | コードの意味 | 文字数 |
|---|---|---|---|
| c | ([]+[][([]+![])[+!![]]+([]+!![])[+[]]])[!![]+!![]+!![]] | ([]+[]['at'])[3] | 55 |
| o | ([!![]]+[][([]+![])[+!![]]+([]+!![])[+[]]])[+!![]+[+[]]] | ([true]+[]['at'])['10'] | 56 |
| ( | ([]+[][([]+![])[+!![]]+([]+!![])[+[]]])[+!![]+[+!![]]] | ([]+[]['at'])['11'] | 54 |
| ) | ([]+[][([]+![])[+!![]]+([]+!![])[+[]]])[+!![]+[!![]+!![]]] | ([]+[]['at'])['12'] | 58 |
| (+[]+[+[]]+[][([]+![])[+!![]]+([]+!![])[+[]]])[+!![]+[+[]]] | (0+[0]+[]['at'])['10'] | 59 |
なお、at関数はECMAScript 2022で追加された関数なので、古いJSFuckコードでは使われない。以前のJSFuckではatではなくfilterを利用していたらしい。
constructor関数
'c'と'o'が手に入ったので、'constructor'という文字列を作ることができるようになった。各クラスのconstructorを文字列に変換すると元のクラス名を含む文字列が得られる。(JSエンジンによって動作が異なる)
なお、表記が長くなりすぎるので、以後配列のインデックスやObjectのプロパティ名となる文字列の部分は、JSFuckコードではなく元の文字列のまま表記する。
[]+(+[])['constructor'] // []+Number.prototype.constructor = 'function Number() { [native code] }'
[]+(![])['constructor'] // []+Boolean.prototype.constructor = 'function Boolean() { [native code] }'
[]+([]+[])['constructor'] // []+String.prototype.constructor = 'function String() { [native code] }'
[]+[]['constructor'] // []+Array.prototype.constructor = 'function Array() { [native code] }'
[]+[]['at']['constructor'] // []+Function.prototype.constructor = 'function Function() { [native code] }'
| 文字列 | コードの意味 | 文字数 |
|---|---|---|
| 'constructor' | 350 | |
| 'm' | ([]+(+[])['constructor'])['11'] | 377 |
| 'b' | ([]+(+[])['constructor'])['12'] | 381 |
| 'g' | ([+[]]+![]+([]+[])['constructor'])['20'] | 388 |
また、Function.prototype.constructorは引数の文字列を関数に変換するという強力な機能を持つ。
const f = Function.prototype.constructor("console.log('hello')")
f() // hello
したがって、この機能を利用すれば任意のJSコードをJSFuckで実行することができる。
しかし現段階では利用できる文字の種類が少なく、JSコードを十分に記述することができない。文字の種類を更に増やす方法を次で調べていく。
任意文字の作成
ここまでの手順で全ての数字とアルファベット小文字が利用可能になった。
ここからはUnicodeに含まれる任意の文字を取り出す方法を考える。
扱える文字の種類を増やすには次のような方法が考えられ、それぞれに利点と欠点(特に各JSエンジンの独自仕様への依存性)が存在する。
- toString
- Unicodeエスケープ
- encodeURI/decodeURI
- escape/unescape
- fromCharCode
- atob/btoa
toString
constructorを用いることで、次のように文字列'toString'が得られる。
([]+[])['constructor']['name'] // 'String' 't' + 'o' + ([]+[])['constructor']['name'] // 'toString'
| 文字列 | コードの意味 | 文字数 |
|---|---|---|
| 'name' | 'n'+'a'+'m'+'e' | 438 |
| 'String' | ([]+[])['constructor']['name'] | 799 |
| 'toString' | 't'+'o'+'String' | 920 |
数値に対してtoString()を引数nを与えながら実行すると、n進数の値に変換される。したがって任意の小文字アルファベットを取得することができる。
ただし、nには2から36の値しか取ることができないので、大文字を得ることはできない。
これまでの過程で出現しなかった小文字は次のように得ることができる。(括弧内の数字はJSFuckでの文字数)
(17)['toString'](36) // (17).toString(36) = 'h' (968) (19)['toString'](36) // (19).toString(36) = 'j' (978) (20)['toString'](36) // (20).toString(36) = 'k' (941) (25)['toString'](36) // (25).toString(36) = 'p' (962) (26)['toString'](36) // (26).toString(36) = 'q' (967) (31)['toString'](36) // (31).toString(36) = 'v' (948) (32)['toString'](36) // (32).toString(36) = 'w' (952) (33)['toString'](36) // (33).toString(36) = 'x' (957) (35)['toString'](36) // (35).toString(36) = 'z' (967)
これらは次のように書くことで短縮することができる。
(101)["toString"](21)[1] // '4h'[1] = 'h' (923) (19)["toString"](20) // 'j' (947) (20)["toString"](21) // 'k' (912) (211)["toString"](31)[1] // '6p'[1] = 'p' (934) (212)["toString"](31)[1] // '6q'[1] = 'q' (938) (31)["toString"](32) // 'v' (928) (32)["toString"](33) // 'w' (937) (101)["toString"](34)[1] // '2x'[1] = 'x' (942) (35)["toString"](36) // 'z' (967)
Unicodeエスケープ
Unicodeエスケープを使う場合、次のようにすることでUnicodeのコードポイントから任意の文字を得ることができる。
[]['at']['constructor']("return '\\u3042'")() // Function("return '\\u3042'")() = 'あ'
toString()によって既に全ての小文字が利用可能なので、残りの必要な部品は次の2つ。
- シングルクォート or ダブルクォート
- '\'
'\'は正規表現から手に入れることができる。
[]+[]["at"]["constructor"]('return RegExp')()() // '/(?:)/'
([]+[]["at"]["constructor"]('return RegExp')()())[0] // '/'
[]+[]['at']['constructor']('return RegExp')()('/') // '/\//'
([]+[]['at']['constructor']('return RegExp')()('/'))[1] // '\'
必要となる大文字'R'と'E'はReferenceErrorあるいはRangeErrorのエラーから手に入れられる。
なお、変数名をfalsefalse = []+![]+![]とすることで任意コード部分の文字列の構成を短縮することができる。
[]+[]['at']['constructor']('try{falsefalse}catch(falsefalse){return falsefalse}')() // 'ReferenceError: falsefalse is not defined'
[]+[]['at']['constructor']('return function(falsefalse){try{falsefalse(Infinity)}catch(falsefalse){return falsefalse}}')()([]['constructor']) // 'RangeError: Invalid array length'
シングルクォートもエラーから手に入れることができる。
(ただしエラーメッセージ部分から取得するのでJSエンジンに強く依存する)
[]+[]['at']['constructor']('return function(falsefalse){try{eval(falsefalse)}catch(falsefalse){return falsefalse}}')()(')') // "SyntaxError: Unexpected token ')'"
encodeURI/decodeURI
encodeURI/decodeURIを使う場合、次のようにすることでUnicodeのコードポイントから任意の文字を得ることができる。
[]['at']['constructor']('return encodeURI')()(' ') // '%20'
[]['at']['constructor']('return decodeURI')()('%e3%81%82') // 'あ'
'R'はReferenceErrorあるいはRangeErrorから取ることができる。
'U'はSyntaxErrorの'Unexpected'という部分から取ることができる。(JSエンジンに強く依存する)
escape/unescape
escape/unescapeを使う場合、次のようにすることでUnicodeのコードポイントから任意の文字を得ることができる。
[]['at']['constructor']('return escape')()('(') // '%28'
[]['at']['constructor']('return unescape')()('%u3042') // 'あ'
必要な手順が非常に少ないことが利点だが、escape/unescapeは現在非推奨に近い扱いを受けているという問題がある。
fromCharCode
fromCharCodeを使う場合、次のようにすることでUnicodeのコードポイントから任意の文字を得ることができる。
''['constructor']['fromCharCode'](12354) // String.fromCharCode(12354) = 'あ'
これを実行するために追加で必要な文字は'C'のみ。
例えば次のようにすることで文字列'fromCharCode'を得ることができる。ただし、今後もし仕様が変わって関数が追加された場合はこのソースコードは動作しなくなり、非常に不安定。
[]['at']['constructor']('return {}')()['constructor']['getOwnPropertyNames'](''['constructor']) // Object.getOwnPropertyNames(String) = ['length', 'name', 'prototype', 'fromCharCode', 'fromCodePoint', 'raw']
[]['at']['constructor']('return {}')()['constructor']['getOwnPropertyNames'](''['constructor'])[3] // 'fromCharCode'
'O'と'P'は次のように取る。
[]+[]['at']['constructor']('return {}')()['constructor'] // []+Function('return {}')()['constructor'] = 'function Object() { [native code] }'
([+[]]+[]['at']['constructor']('return {}')()['constructor'])[+!![]+[+[]]] // ([0]+Function('return {}')()['constructor'])['10'] = 'O'
[]+[]['at']['constructor']('return async function(){}')()() // []+Function('return async function(){}')()([]) = '[object Promise]'
(+[]+[+[]]+[]['at']['constructor']('return async function(){}')()([]))[+!![]+[+[]]] // (0+[0]+Function('return async function(){}')()([]))[10] = 'P'
atob/btoa
btoaはISO-8859-1で表現されたバイナリー文字列をBase64にエンコードする関数で、atobはBase64文字列をデコードする関数。
atob/btoaはECMAScriptで定義された関数ではなく、Webブラウザー環境向けの機能としてWHATWG HTML Living Standardで定められたJSのAPIの一つである。したがって、これらの関数は全てのJSの実装で利用できるわけではないことに注意が必要。(Node.jsのようなWebブラウザーではないJS環境では使えない)
Base64では、バイナリーを6-bitずつ取り出して64進数(A-Za-z0-9+/)で表現してASCIIの文字列として返す。(更に、文字数が4の倍数になるように末尾を文字'='で埋める)
btoa('base64') // 'YmFzZTY0'
atob('YmFzZTY0') // 'base64'
この仕組みを用いれば、任意の大文字アルファベットを取り出すことができる。
例えば'C'はASCIIでは0x43 = 0b01000011、Base64では0b000010に対応するので、次のように調整すれば'C'を得ることができる。
// 00110000 00101011 -> 001100 000010 101100 = 'MCs='
btoa('0+')
// 110100 110100 001101 011010 ... -> 11010011 01000011 01011010 ... = 'ÓCZ5ö¥±'
atob('00NaNfalse')
JSFuckで書く場合は次のようになる。
[]['at']['constructor']('return btoa')()('0+') // 'MCs='
[]['at']['constructor']('return atob')()('00NaNfalse') // 'ÓCZ5ö¥±'
Base64の文字列(の意味のある部分)の長さは4n+1になることはないので、4n+1の長さの文字列をatobに入れるとエラーが発生する。上記の例では'00NaN'が5文字なので、エラーを回避するために末尾に'false'を付与している。
次のコードは、'C'を取り出すことのできる[]['at']['constructor']('return btoa')()('0+')[1]と同義のJSFuckコードである。
[][([]+![])[+!![]]+([]+!![])[+[]]][([]+[][([]+![])[+!![]]+([]+!![])[+[]]])[!![]+!![]+!![]]+([!![]]+[][([]+![])[+!![]]+([]+!![])[+[]]])[+!![]+[+[]]]+([]+[][[]])[+!![]]+([]+![])[!![]+!![]+!![]]+([]+!![])[+[]]+([]+!![])[+!![]]+([]+[][[]])[+[]]+([]+[][([]+![])[+!![]]+([]+!![])[+[]]])[!![]+!![]+!![]]+([]+!![])[+[]]+([!![]]+[][([]+![])[+!![]]+([]+!![])[+[]]])[+!![]+[+[]]]+([]+!![])[+!![]]](([]+!![])[+!![]]+([]+!![])[!![]+!![]+!![]]+([]+!![])[+[]]+([]+[][[]])[+[]]+([]+!![])[+!![]]+([]+[][[]])[+!![]]+(+[]+[+[]]+[][([]+![])[+!![]]+([]+!![])[+[]]])[+!![]+[+[]]]+([]+(+[])[([]+[][([]+![])[+!![]]+([]+!![])[+[]]])[!![]+!![]+!![]]+([!![]]+[][([]+![])[+!![]]+([]+!![])[+[]]])[+!![]+[+[]]]+([]+[][[]])[+!![]]+([]+![])[!![]+!![]+!![]]+([]+!![])[+[]]+([]+!![])[+!![]]+([]+[][[]])[+[]]+([]+[][([]+![])[+!![]]+([]+!![])[+[]]])[!![]+!![]+!![]]+([]+!![])[+[]]+([!![]]+[][([]+![])[+!![]]+([]+!![])[+[]]])[+!![]+[+[]]]+([]+!![])[+!![]]])[+!![]+[!![]+!![]]]+([]+!![])[+[]]+([!![]]+[][([]+![])[+!![]]+([]+!![])[+[]]])[+!![]+[+[]]]+([]+![])[+!![]])()(+![]+(+[+!![]+([]+!![])[!![]+!![]+!![]]+[+!![]]+[+[]]+[+[]]]+[])[!![]+!![]])[+!![]] // 'C' (1114)
[]
[([]+![])[+!![]]+([]+!![])[+[]]] // ['at']
[([]+[][([]+![])[+!![]]+([]+!![])[+[]]])[!![]+!![]+!![]]+([!![]]+[][([]+![])[+!![]]+([]+!![])[+[]]])[+!![]+[+[]]]+([]+[][[]])[+!![]]+([]+![])[!![]+!![]+!![]]+([]+!![])[+[]]+([]+!![])[+!![]]+([]+[][[]])[+[]]+([]+[][([]+![])[+!![]]+([]+!![])[+[]]])[!![]+!![]+!![]]+([]+!![])[+[]]+([!![]]+[][([]+![])[+!![]]+([]+!![])[+[]]])[+!![]+[+[]]]+([]+!![])[+!![]]] // ['constructor']
(([]+!![])[+!![]]+([]+!![])[!![]+!![]+!![]]+([]+!![])[+[]]+([]+[][[]])[+[]]+([]+!![])[+!![]]+([]+[][[]])[+!![]]+(+[]+[+[]]+[][([]+![])[+!![]]+([]+!![])[+[]]])[+!![]+[+[]]]+([]+(+[])[([]+[][([]+![])[+!![]]+([]+!![])[+[]]])[!![]+!![]+!![]]+([!![]]+[][([]+![])[+!![]]+([]+!![])[+[]]])[+!![]+[+[]]]+([]+[][[]])[+!![]]+([]+![])[!![]+!![]+!![]]+([]+!![])[+[]]+([]+!![])[+!![]]+([]+[][[]])[+[]]+([]+[][([]+![])[+!![]]+([]+!![])[+[]]])[!![]+!![]+!![]]+([]+!![])[+[]]+([!![]]+[][([]+![])[+!![]]+([]+!![])[+[]]])[+!![]+[+[]]]+([]+!![])[+!![]]])[+!![]+[!![]+!![]]]+([]+!![])[+[]]+([!![]]+[][([]+![])[+!![]]+([]+!![])[+[]]])[+!![]+[+[]]]+([]+![])[+!![]]) // ('return btoa')
()
(+![]+(+[+!![]+([]+!![])[!![]+!![]+!![]]+[+!![]]+[+[]]+[+[]]]+[])[!![]+!![]]) // ('0+')
[+!![]] // [1]
この方法で'C'を得ることができたので、ASCII以外の文字はfromCharCodeから作り出せば良い。
まとめ
Unicodeの任意の文字を取り出す方法を次の図にまとめる。(toStringはほぼ全てに影響するので省略)
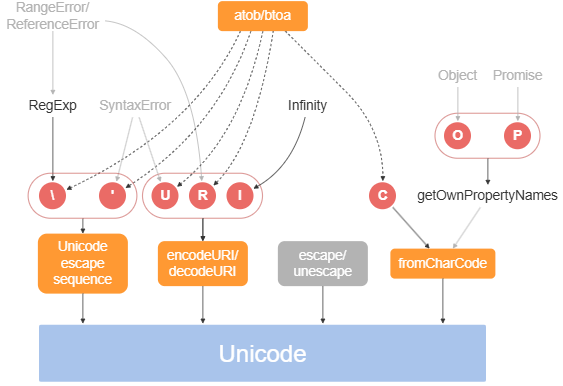
Unicodeの任意の文字を取り出す方法
値や関数のショートカット登録
よく使う値や関数は次のようにショートカット登録しておくことで、JSFuckコード全体に要する文字数を抑えることができるようになる。
例えば、fromCharCodeは1回呼び出すごとにJSFuckコードで(実装にもよるが)4000字以上も必要になる。
そこで、次のようにArray.prototype.atのプロパティにfromCharCodeを呼び出すショートカットを登録すると、2回目以後の呼び出しを41文字(+引数の分)だけで表現できるようになる。
[].at.false = String.fromCharCode []['at'][false](12354) // 'あ'
JSFuckでショートカットを登録するには、次のように任意コード実行を利用する。
[]['at']['constructor']('return function(falsefalse){falsefalse.false=String.fromCharCode}')()([]['at'])
[]['at'][false](12354) // 'あ'
参考
- jsfuck/jsfuck.js at main · aemkei/jsfuck · GitHub
- javascript - Alternative way to get "C" letter in jsfuck - Stack Overflow
- restricted source - JSFuck Golf - Hello World - Code Golf Stack Exchange
- JSFuckから理解するECMAScriptの仕様 - Kokudoriing
- 本格JavaScript記号プログラミング(1) 6種類の記号だけでJavaScriptを書こう #Esolang - Qiita
- 5 種の記号だけで JavaScript(w/ pipeline operator) を書く | La Verda Luno
- JSFuck - プログラミング雑ネタ集
- 6つの記号でjavascript【アドベントカレンダー2019 2日目】 | 東京科学大学デジタル創作同好会traP
- JSFuck 入门,仅用六个字符编写你的程序 - My Codes
- 【プログラミング】JSFuckという言語を知ってるかい? - YouTube