[Stable Diffusion] AUTOMATIC1111の導入手順・機能解説
この記事では、Stable Diffusion (SD)をローカルで利用する方法、特にAUTOMATIC1111の機能と使い方を解説する。
関連記事
- DDPM: Denoising Diffusion Probabilistic Models
- DDPMの関連技術
- Stable Diffusionのモデル構造
- [Stable Diffusion] AUTOMATIC1111の導入手順・機能解説 (本記事)
- [Stable Diffusion] 追加学習の理論
- [Stable Diffusion] LoRAの学習手順
- [Stable Diffusion] ControlNetとReference-Only
- [Stable Diffusion] SDXL
目次
Stable Diffusionをローカルで利用する方法
diffusers

Hugging Faceが提供するStable DiffusionのPythonパッケージ。
Pythonのコンソール上から実行する。
NMKD Stable Diffusion GUI

2022年8月30日に公開されたStable DiffusionのWindows用GUI。N00MKRAD氏が開発。
インストーラーから導入できるので初心者でも始めやすい。
Stable Diffusion web UI (AUTOMATIC1111)

2022年9月頃に登場したStable DiffusionのWeb UI。AUTOMATIC1111氏が開発。
非常に多機能で、最新の技術への対応が早いことが特徴。
似た名前のWeb UIが複数開発されているので、開発者の名前を取ってWeb UIそのものを「AUTOMATIC1111」と呼ぶことが多い。
AUTOMATIC1111の画面
ComfyUI
2023年1月に登場したStable DiffusionのWeb UI。comfyanonymous氏が開発。
Stable Diffusionの処理過程がグラフィカルに可視化されるノードベースのUI。
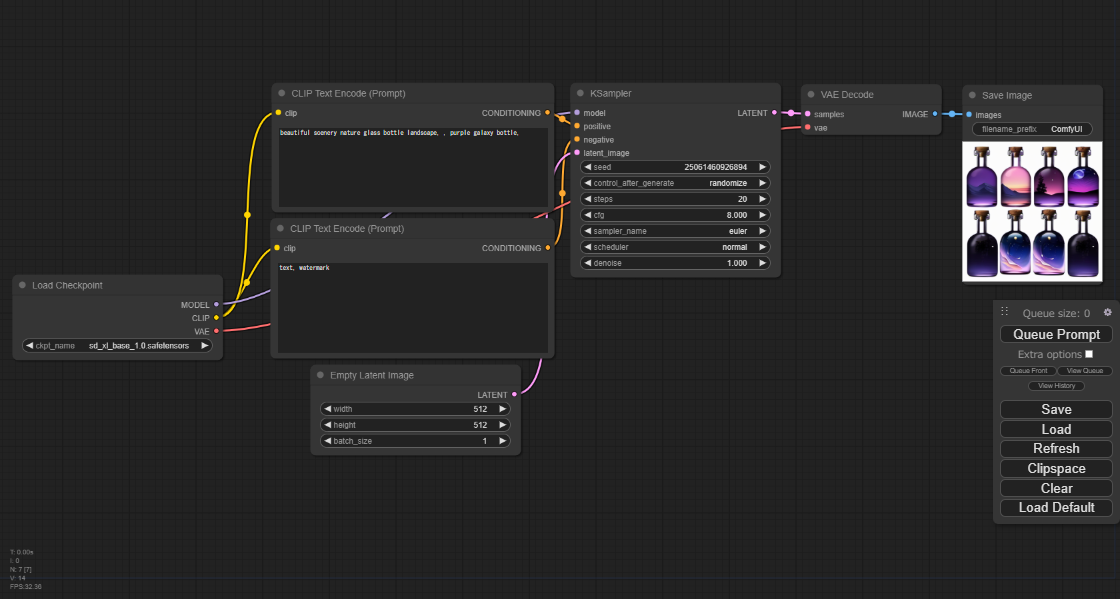
ComfyUIの画面
StableSwarmUI
2023年7月28日に登場したStable Diffusionの公式のweb UI。
AUTOMATIC1111のインストール手順
以下にAUTOMATIC1111の導入手順を記載する。
Windowsでの手順を記すが、Linuxにも導入できることを確認している。
環境
導入したPC環境は以下。
| 項目 | 内容 |
|---|---|
| OS | Windows 11 Pro |
| グラフィックボード | NVIDIA GeForce RTX 4070 |
| CPU | Intel Core i7-13700F |
| メモリ | 32GB (16GBx2) |
| ストレージ | 1TB SSD |
Gitをインストール
64-bit Git for Windows Setupからインストーラーをダウンロードして実行。
Git - Downloading Package
全てデフォルトの選択のままインストールして問題ない。
(参考) インストールされたGitのバージョンの確認
エクスプローラー上の右クリックメニュー→「その他のオプションを表示」→「Open Git Bash here」でGit Bashを開く。
git -vでバージョンを確認。インストールされたバージョンは「2.41.0.windows.3」。
Python 3.10をインストール
以下のリンクからインストーラー(Python 3.10.6)をダウンロードして実行。
https://www.python.org/ftp/python/3.10.6/python-3.10.6-amd64.exe
Add python.exe to PAHTにチェックを入れると、環境変数のPATHにPythonが追加される。
その他は全てデフォルトの選択のままインストール。
(参考) インストールされたPythonのバージョンの確認
コマンドプロンプトで「python -V」を実行して、インストールされたことを確認。
AUTOMATIC1111
Git Bashで以下のコマンドを実行し、GitからAUTOMATIC1111のリポジトリをクローンする。(バージョンは1.5.1)
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
起動する前にstable-diffusion-webui/webui-user.batを開き、COMMANDLINE_ARGSに値を追加する。
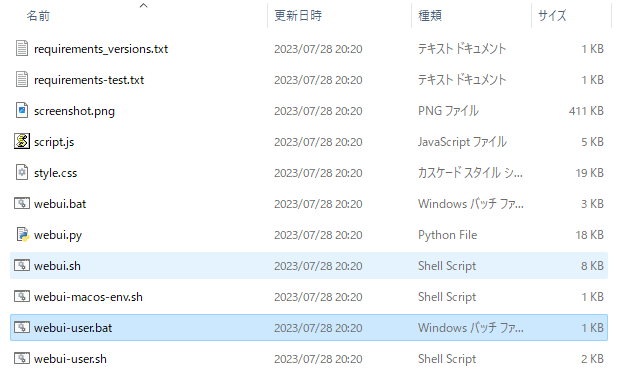
xFormersをインストールするために--xformersを追加。
また、LAN内の別の端末からもアクセスできるように--listenを追加。
--listenを追加した場合、拡張機能のインストールが無効化されてしまうので、--enable-insecure-extension-accessを追加して再び有効化。
set COMMANDLINE_ARGS=--xformers --listen --enable-insecure-extension-access
webui-user.batを実行。
必要なライブラリ(PyTorch, xFormersなど)は自動でインストールされる。また、PyTorchにはCUDAとcuDNNが同梱されており、これらも自動でインストールされる。
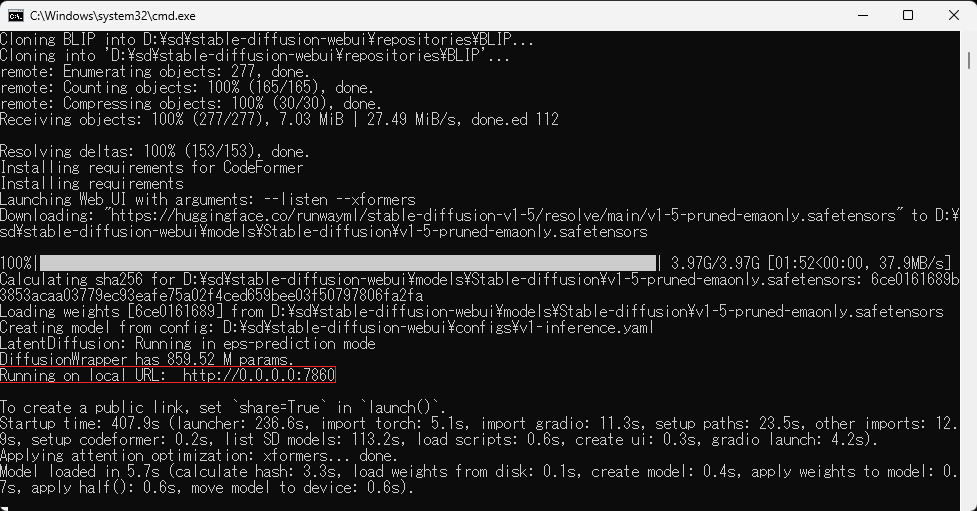
「Running on local URL:」のログが表示されたら、webブラウザーで「http://localhost:7860/」に接続することで利用できる。
PyTorch
PyTorchはFacebook (Meta)によって開発された深層学習ライブラリ。GoogleのTensorflowと双璧をなすライブラリーであり、Tensorflowと比べて扱いやすいことから研究者に人気があると言われている。
AUTOMATIC1111ではwebui-user.batの実行時に自動でインストールされる。
xFormers
xFormersは、Transformerを高速化しVRAM効率を改善することのできるPyTorchのライブラリー。
2023年3月16日にリリースされたPyTorch 2.0ではxFormersと同様の効果が得られるFlashAttention(sdpa_flash)と、xFormersのAttention(sdpa_mem_eff)が標準で備わっている。しかし、xFormersを別途インストールした方が消費VRAMが少なく済むと言われている。
2023年7月17日にはFlashAttention-2が発表された。今後xFormersからFlashAttention-2に置き換わる流れが来るかもしれない。
AUTOMATIC1111では、webui-user.batに上記のオプションを追加して起動するだけで、起動時にxFormersが自動でインストールされる。
CUDA
CUDA(Compute Unified Device Architecture)はNVIDIA製のGPUで並列計算を実行するためのコンパイラー・ライブラリー群。
個別にインストールすることもできるが、PyTorchを利用する場合は自動でインストールされる。
cuDNN
cuDNNはCUDAで深層ニューラルネットワークを扱うためのライブラリー。
個別にインストールすることもできるが、PyTorchを利用する場合は自動でインストールされる。
cuDNNを最新版に更新する必要があるときは、NVIDIAのサイトからcuDNNをダウンロードし(アカウント登録が必要)、stable-diffusion-webui/venv/Lib/site-packages/torch/lib内にdllファイルを上書きする。
cuDNN Archive | NVIDIA Developer
(参考) インストールされたライブラリーのバージョンの確認
「stable-diffusion-webui/venv/Scripts」の直下にあるpip.exeに対して、コマンドプロンプトで「pip freeze」を実行することでPyTorchとxFormersのバージョンを確認することができる。
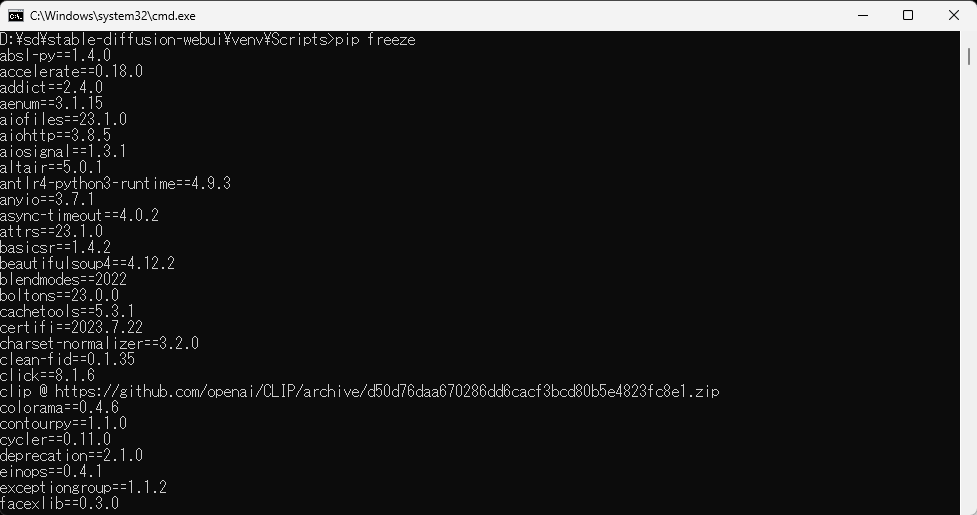

torch==2.0.1+cu118 xformers==0.0.20
がインストールされていることを確認。
また、venvのpythonを起動して以下を実行することで、PyTorchに含まれるCUDAとcuDNNのバージョンを確認することができる。
import torch torch.version.cuda torch.backends.cudnn.version()
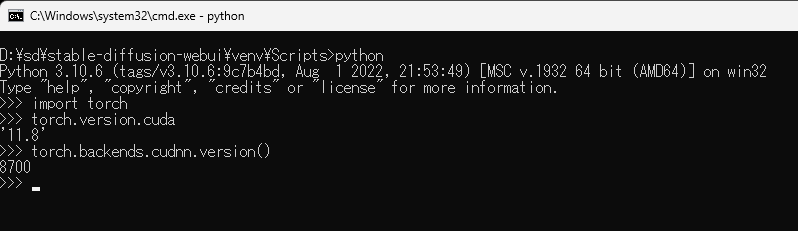
CUDAのバージョンは11.8、cuDNNのバージョンは8.7.0。
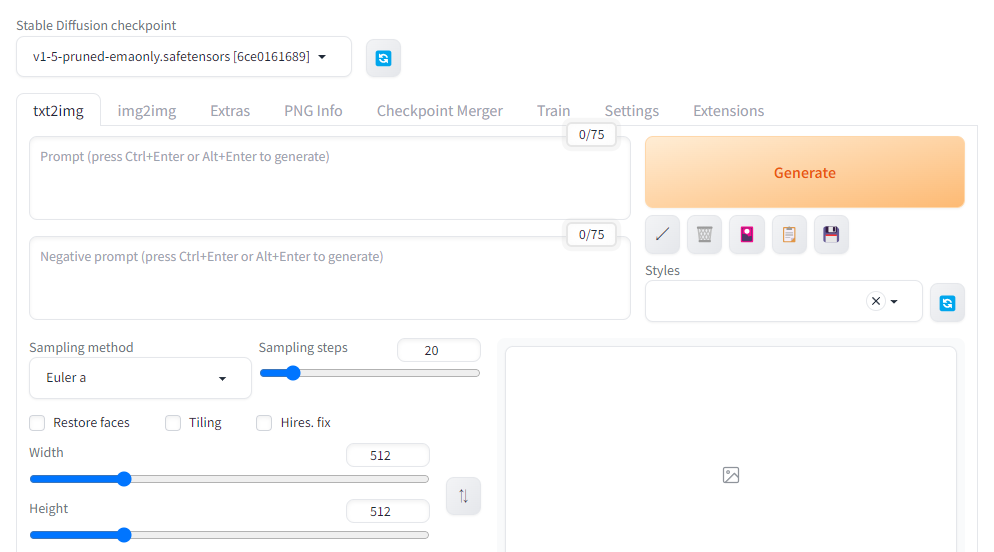
AUTOMATIC1111の使い方 (基本機能)
txt2imgはSDやAUTOMATIC1111の基本的な機能。利用者が入力した文章から画像を生成する。
画面項目
txt2imgの画面
項目 |
説明 |
|---|---|
| Stable Diffusion checkpoint |
学習済みのU-NetとTE(Text Encoder)のパラメーターファイル。俗に「モデル」と呼ばれる。 |
| SD VAE | 学習済みのVAEのパラメーターファイル。この項目は、「Settings」→「User interface」→「Quicksettings list」に「sd_vae」を追加設定することで表示される。 |
| Prompt | 出力したい画像を表す文章やタグを入力する。Ctrl+↑or↓で単語の影響の強弱を変更することもできる(後述)。 |
| Negative prompt | 出力したくない要素を表す文章やタグを入力する。詳しくは後述。 |
| Sampling method | U-Netが出力する予測ノイズを利用して、次のタイムステップの画像潜在ベクトルを生成するサンプラー。DDIMの他に、スコアベースモデルに基づく理論から実装された様々なサンプラーが利用できる。 |
| Sampling steps | 完全なノイズから画像を生成するまでのステップ数。Sampling methodには、ここで指定した値と同じ回数U-Netを実行するものと、ここで指定した値の2倍の回数U-Netを実行するものがある。 |
| Width/Height | 出力する画像の幅と高さ。 |
| Batch count | 画像生成を繰り返す回数。 |
| Batch size | 1回の画像生成で同時に出力する画像の枚数。この値を大きくしすぎると、VRAM不足で生成に失敗する。最終的に(Batch count)×(Batch size)枚の画像が生成されることになる。 |
| CFG Scale | CFGの重み。 |
| Seed | 乱数のシード。-1を指定した場合、web UI側がランダムに選択する。複数枚を生成する場合は1枚ごとにSeedの値が1ずつ増えていく。Extraにチェックを入れると更に詳細な乱数の設定ができる(後述)。 |
| Script | 「None」を選ぶと普通に画像を生成する。「X/Y/Z plot」を選ぶと、設定値を変化させた比較表を1枚の画像に出力することができる。 |
「Generate」ボタンの下にある花札のアイコンを押と、「extra network」の画面が表示される。
SDは利用者たちによって様々な追加学習データ(LoRAなど)が公開されている。ダウンロードしたパラメーターファイルを予めstable-diffusion-webuiのmodelフォルダーに配置しておくことで、extra networkの画面から追加学習データを選択して適用することができる。
使用例
この例では追加学習済みモデル「Realistic Vision」を利用する。
SDの様々なモデルやLoRAは、Civitaiというサイトで共有されている。(Hugging Faceなど他のサイトでも共有されている)
Realistic Visionは以下のリンクからダウンロードできる。
Realistic Vision V5.0 - v5.0 (VAE) | Stable Diffusion Checkpoint | Civitai
ダウンロードしたチェックポイントはstable-diffusion-webui/models/Stable-diffusionの下に配置する。
(チェックポイントの他に、LoRAという形式のパラメーターファイルも多く投稿されている。LoRAをダウンロードした場合はLoraフォルダーに配置する。)
web UIを起動。
この例では以下のように設定値を入力する。
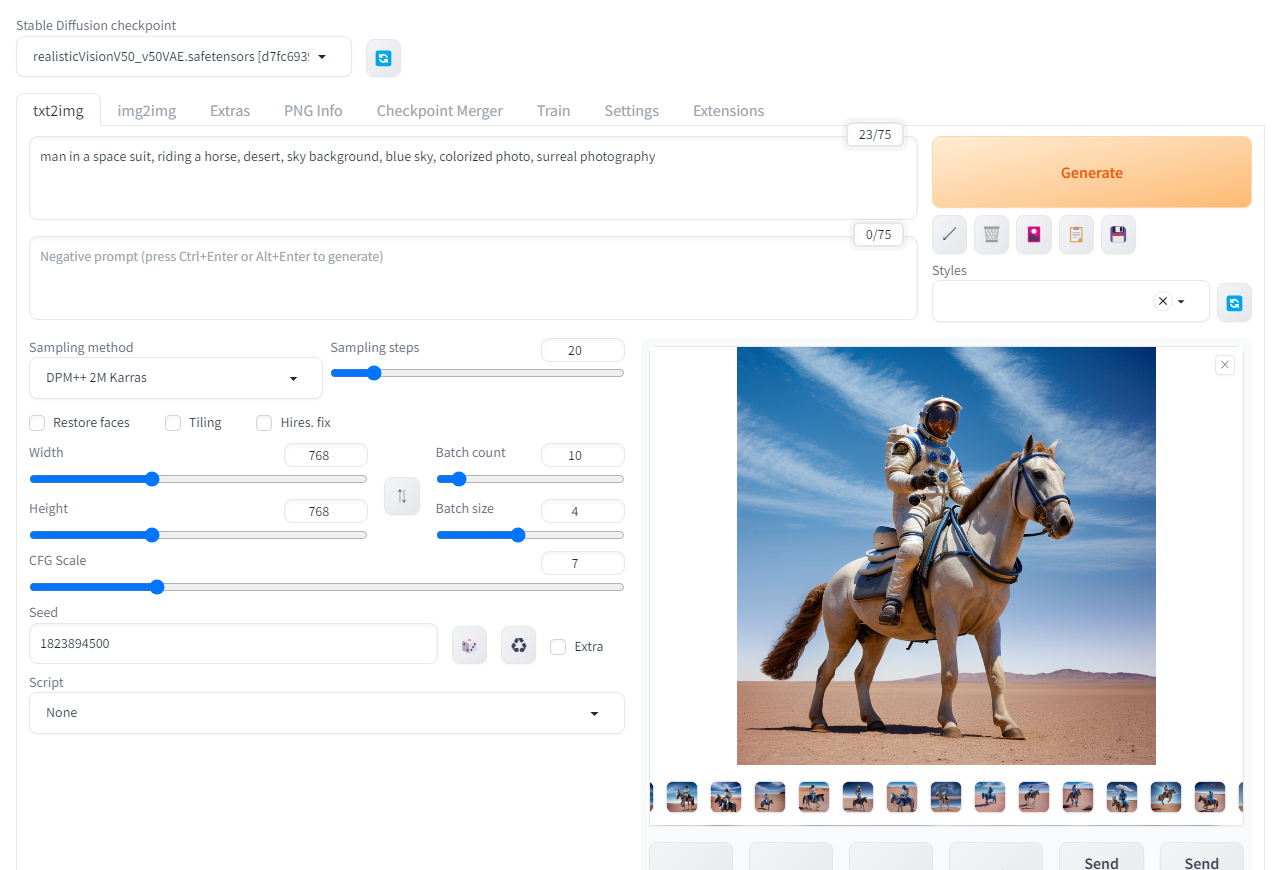
Stable Diffusion checkpointで「realisticVision」を選択。
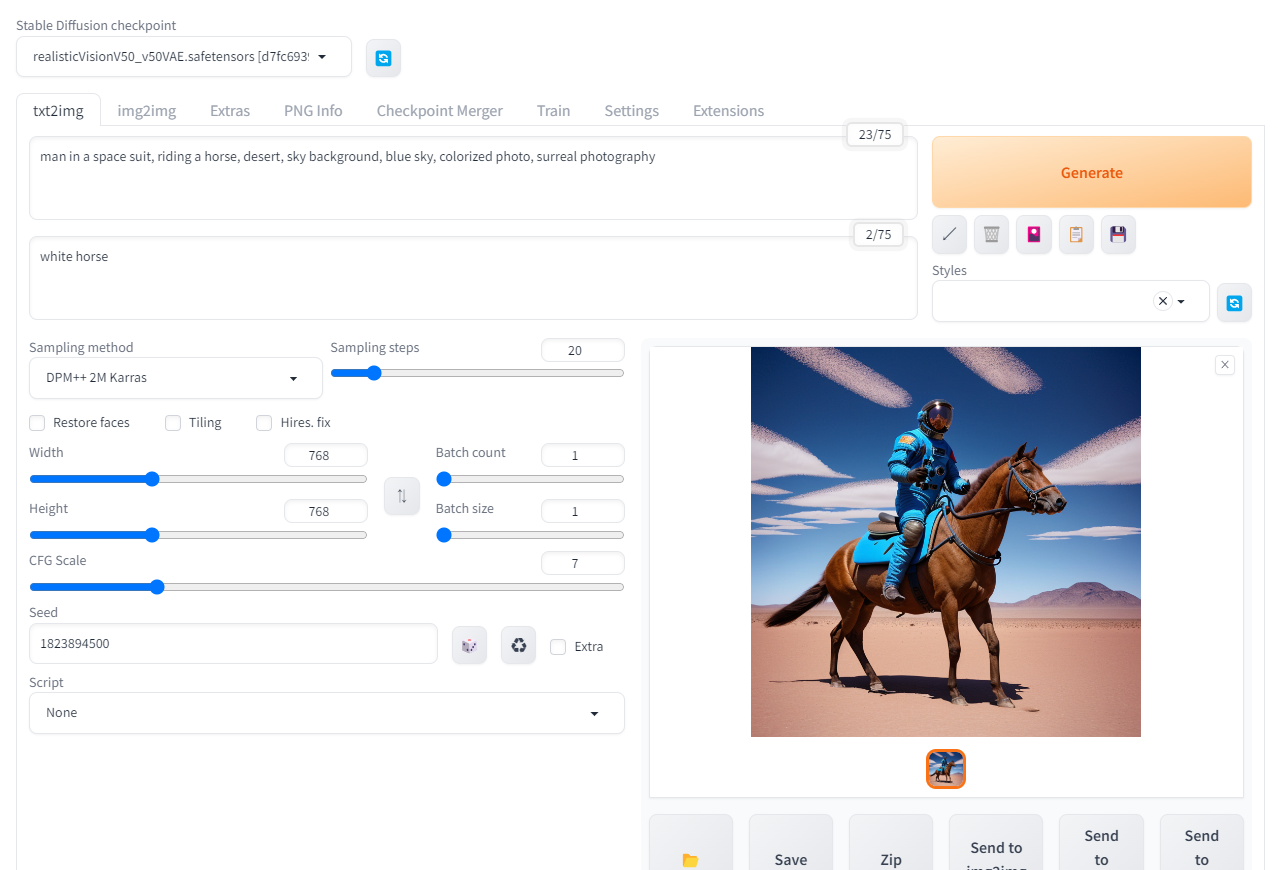
Promptに「man in a space suit, riding a horse, desert, sky background, blue sky, colorized photo, surreal photography」と入力。
Sampling methodは「DPM++ 2M Karras」を選択。
Width=Height=768, Batch count=10, Batch size=4に設定。
Seedは「1823894500」に設定。(この記事の結果を再現するための値であり、通常の使用時は-1で問題ない)
その他の設定は規定の値のまま。
Generateボタンを押すと10×4=40枚の画像が生成される。
txt2imgの画面

出力された画像
生成した画像は「stable-diffusion-webui/outputs/txt2img-images」にも自動で保存されている。
生成過程の可視化
「stable-diffusion-webui/repositories/k-diffusion/k_diffusion/sampling.py」の「sample_dpmpp_2m」を直接次のように編集することで、生成途中の潜在ベクトルをそれぞれ可視化してみた。
old_denoised = None
for i in trange(len(sigmas) - 1, disable=disable):
# ここから追加
from torchvision.utils import save_image
rgb = model.inner_model.inner_model.decode_first_stage(x)
rgb = torch.clamp((rgb + 1.0) / 2.0, min=0.0, max=1.0)
save_image(rgb[0], rf'D:\tmp\generate_process_{i}.png')
# ここまで
denoised = model(x, sigmas[i] * s_in, **extra_args)
if callback is not None:
callback({'x': x, 'i': i, 'sigma': sigmas[i], 'sigma_hat': sigmas[i], 'denoised': denoised})

生成途中の潜在ベクトルを可視化した画像
また、\(z_t=\alpha_t z_0 + \sigma_t \varepsilon\)の関係から予測される各timestepにおける\(x_0=Decode(z_0)\)は次のようになる。
(sd_save_intermediate_imagesという拡張機能で出力)

各timestepで予測される\(x_0\)を可視化した画像
AUTOMATIC1111のその他の機能解説
AUTOMATIC1111の全ての機能はGitのWikiで解説されている。
Features · AUTOMATIC1111/stable-diffusion-webui Wiki · GitHub
ここでは、その中でも主な機能や、技術的に解説が必要な機能を紹介する。
単語の強調 (Prompt Attention/emphasis)
()や[]を使うことで、promptに含まれる各単語の影響の強さを変更することができる。
(word)とすると1.1倍、((word))とすると1.21倍になる。[word]とすると1/1.1倍、[[word]]とすると1/1.21倍になる。(word:1.5)などとすることで、倍率を具体的に指定することも可能。(prompt入力中にCrtl+↑ or ↓でも操作可能)
prompt attention
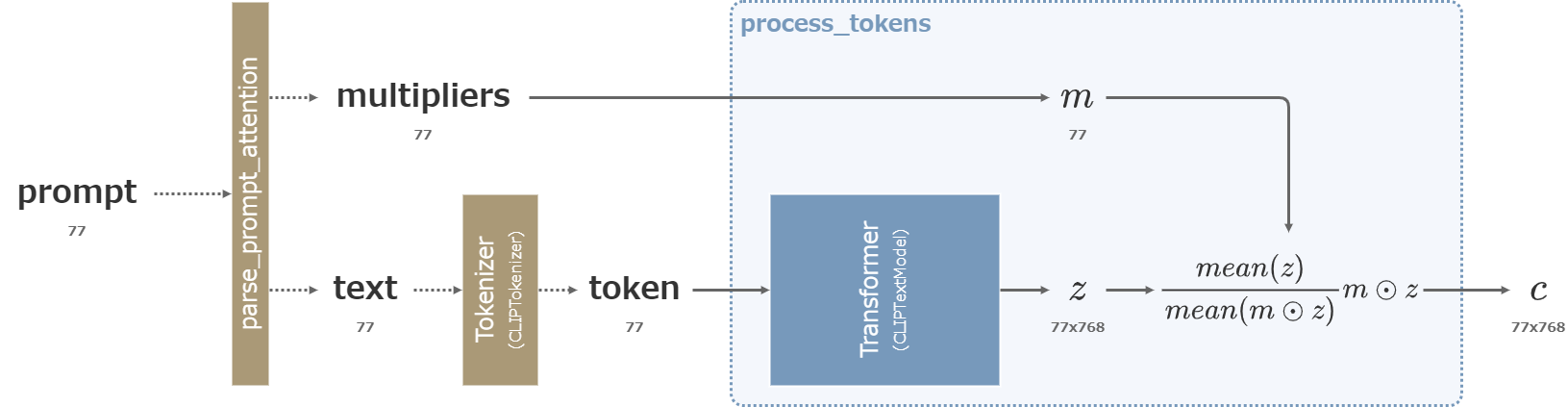
入力されたpromptは単語に分割され、上記の強調構文に従って各単語の倍率が求められる。
強調の括弧を取り除いた文章は通常通りトークン化された後にTransformerを通って77x768のベクトル\(z\)へと変換される。
その後、\(z\)に含まれる77個のベクトルを\(m\)の各成分によって重み付け、\(z\)の77x768個の全成分の平均が重み付け前後で変わらないように正規化する。
重み付けは0や負の値を指定することも可能。ただし、Transformerによって他の位置の単語にも影響を与えた後に重み付けするので、重みを0にしてもその単語の影響を完全に消すことはできない。
Stable Diffusion以前では、Midjourney (2022/07)に「prompt weights」という名称で実装されていた。
AUTOMATIC1111には2022年9月29日に実装された。
使用例
以下は、Photo of salami and basil pizzaのsalamiとbasilをそれぞれ強調した結果の比較。

Negative prompt
Negative promptに文章やタグを入力すると、その要素は生成画像から除外されやすくなる。
記法はPromptと同様で、上記の強調も利用できる。
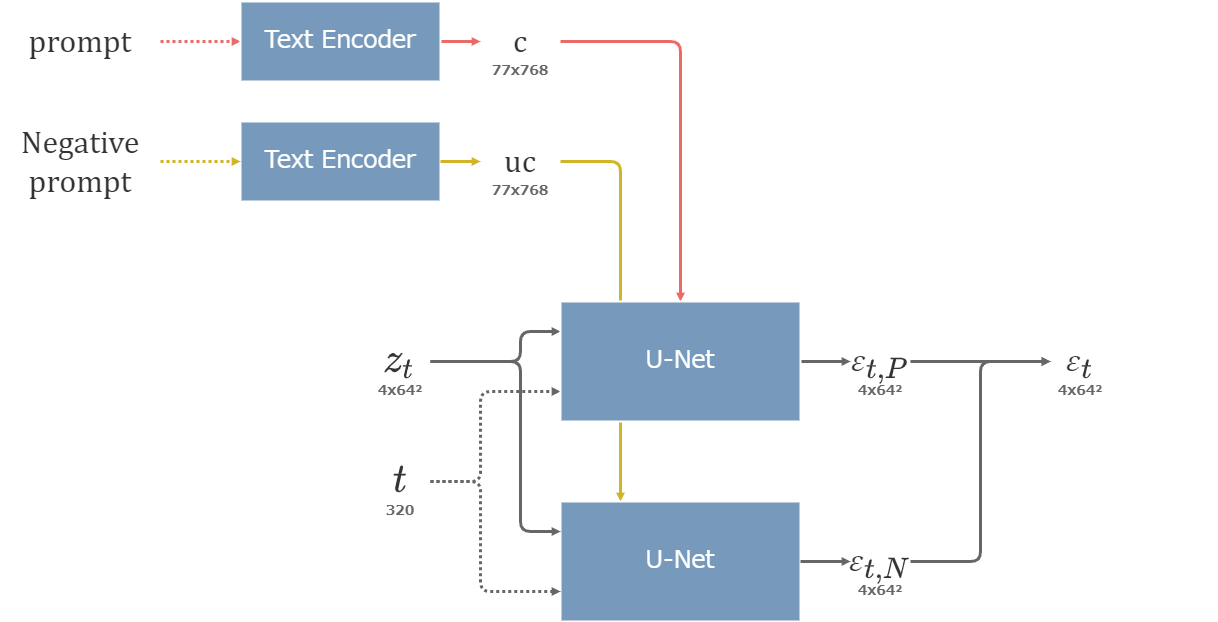
Negative promptに入力した文章は、CFGにおける空の文章の代わりにTEに入力される。
つまり、U-NetのAttentionでPromptの潜在ベクトルを受け取った場合の出力を\(\varepsilon_P\)、Negative promptの潜在ベクトルを受け取った場合の出力を\(\varepsilon_N\)とすると、CFGによる出力の統合は以下のように行われる。
\begin{align} \varepsilon = \varepsilon_N + cfg\_scale (\varepsilon_P - \varepsilon_N) \end{align}
以下の図のように、Positive promptのモード(=尤度が極大となる点)とNegative promptのモードが近いとき、単にPositive promptだけで画像を生成するとNegativeのモードに近い要素も含まれてしまう可能性がある。CFGを適用することで、明示的にNegativeのモードから遠ざかるように画像を生成する効果を得ることができる。
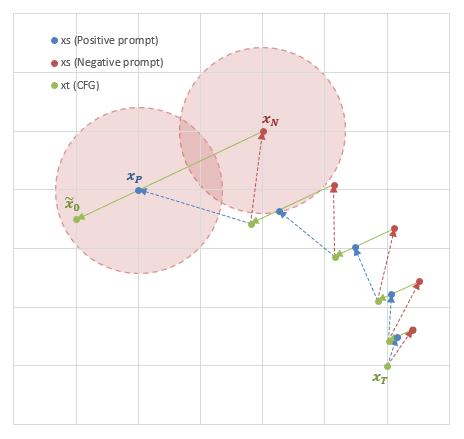
Negative promptを用いたCFGの概略図
AUTOMATIC1111には2022年9月の公開当初から実装されている。AUTOMATIC1111氏によれば、この手法を導入したのは同氏が初めてらしい。
使用例
txt2imgの例でNegative promptに「white horse」を指定すると、白馬が画像に登場しにくくなる。

img2img
img2imgは文章だけではなく画像も指定し、似た構図の画像を生成する機能。
指定画像のVAEによる埋め込みに対してDenoising strengthの割合のノイズを付与し、その埋め込みを起点にしてU-Netが画像を生成していく。
Denoising strength値が小さいほど指定した画像に近い画像が出力されるが、画像の変化は少なくなる。逆に、値を大きくするとpromptで指定した要素が多く含まれるようになるが、指定画像の構図からは離れていく。

img2imgの流れ
このような画像生成の仕組み自体は2020年6月のDDPMの論文の時点で紹介されていて、Stable Diffusion公式でもimg2imgが実装されている。また、img2imgはSDEditという名前でも知られている。
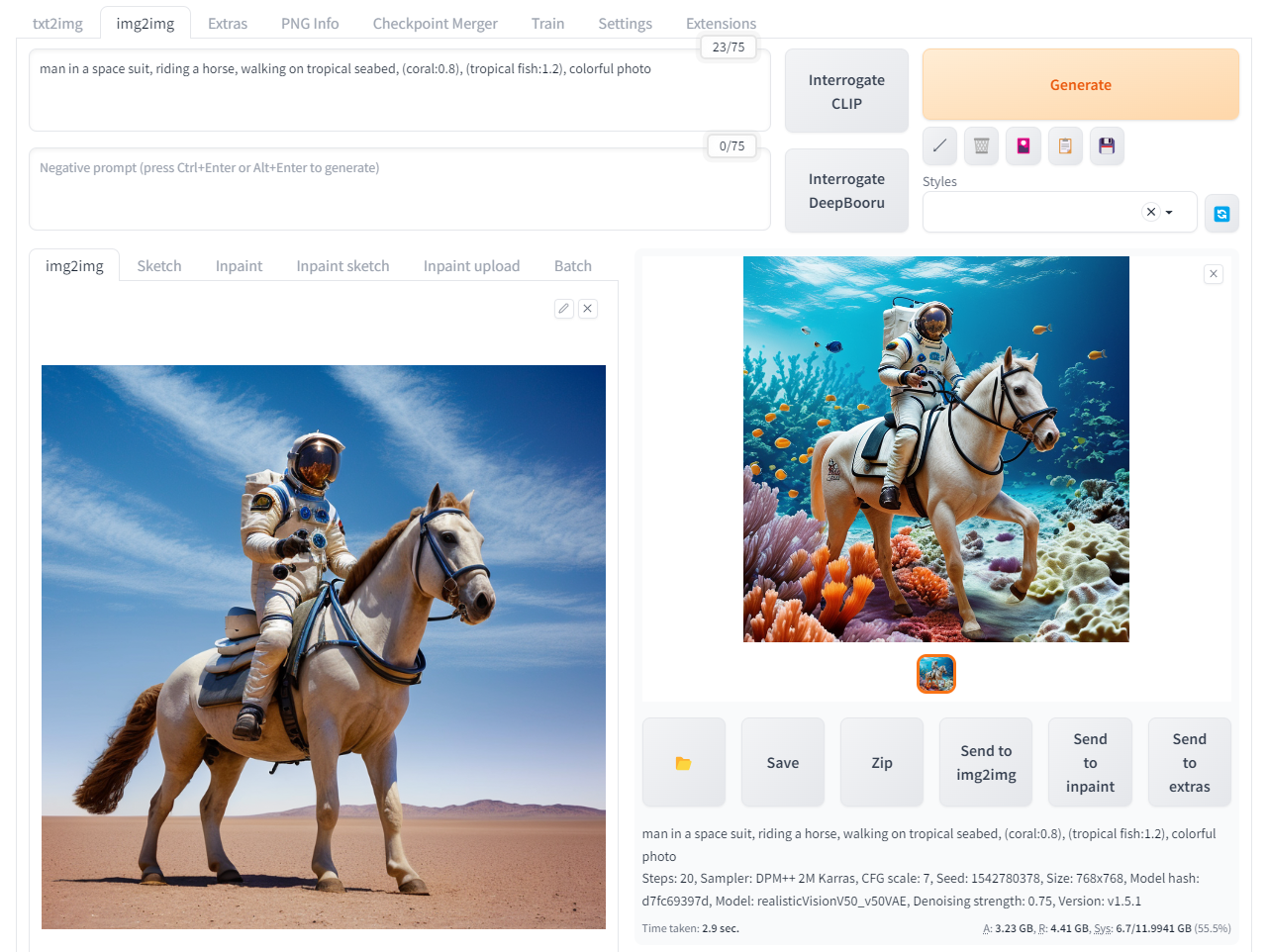
使用例
txt2imgで生成した画像を読み込み、以下の設定で出力した。
- Sampling method = DPM++ 2M Karras
- prompt = "man in a space suit, riding a horse, walking on tropical seabed, (coral:0.8), (tropical fish:1.2), colorful photo"
- Denoising strength = 0.75 (デフォルト)
- Seed = 1542780378
- その他デフォルト
img2imgの画面

出力された画像
img2imgタブでは、「Interrogate CLIP」あるいは「Interrogate DeepBooru」のボタンを押すことで、画像からpromptを自動で推測することもできる。
inpaint
inpaintは、入力画像の一部だけを生成することが可能となるimg2imgの副次的な機能。
利用者が画像内の領域を指定すると、その領域を表すマスクがまず64x64のサイズに縮小される。
入力画像はimg2imgと同じように潜在ベクトル\(z_0\)へと変換された後にDenoising strength分のノイズがかけられる。その最初のステップを\(z_t\)とすると、タイムステップ\(t\)での\(z_0\)の予測値は、64x64の領域の内側が \(z_t\)からU-Netで予測された\(z_0\) であり、外側が入力画像の潜在ベクトル\(z_0\)そのものになるよう合成される。
そして、合成された\(x_0\)をサンプラーが利用して次のタイムステップ\(z_s\)が出力される。この繰り返しによって最終的な出力画像\(z_0\)を得る。
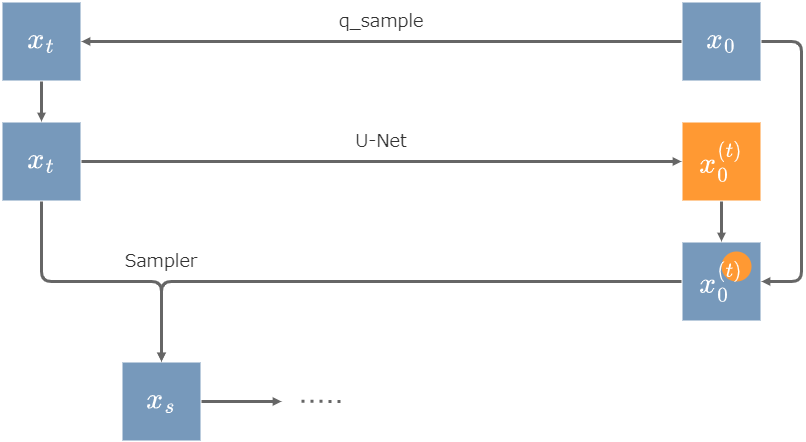
inpaintの概要図。画像内の右上に円状の領域を指定した場合。画像の合成は64x64の空間内で行われる。
つまり利用者が領域を指定したとき、その内側はSDがノイズから生成し、外側は常に入力画像に由来する値になる。生成のステップが進むほど外側は元の入力画像に近い値となる一方で、内側はノイズからの生成過程によって新たな像を生み出すことになる。
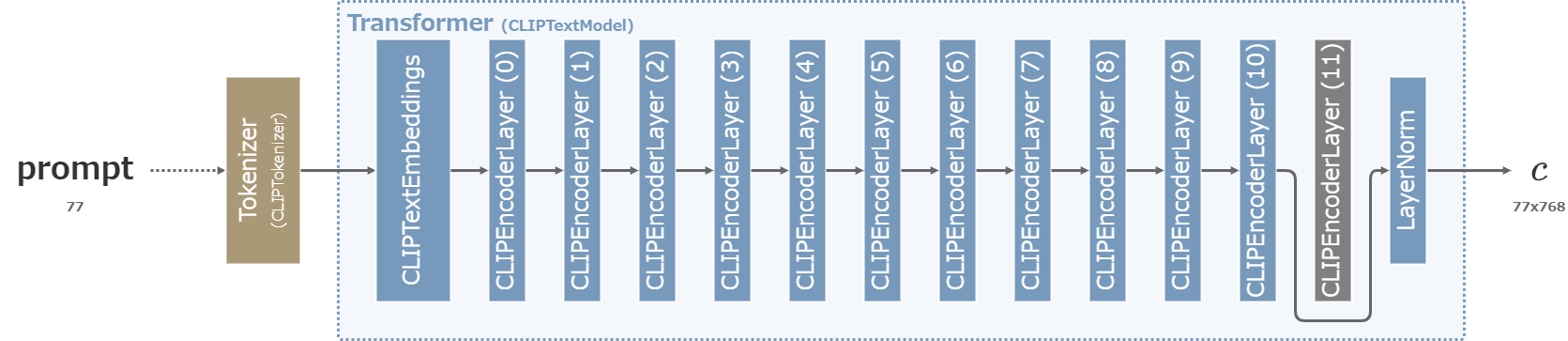
CLIP skip
CLIPは全12層の内、最後の12層目で突然値が大きく変化することが知られていた。
そこで、Imagen (2022/05)やNovelAI (2022/10/03)ではCLIPの出力そのもの(=12層目の出力)ではなく、11層目の出力を利用するという方法が取られた。このようなテクニックをNovelAIはCLIP skipと名付けた。
Clip skip=2
AUTOMATIC1111では、「Settings」→「User interface」→「Quicksettings list」に「CLIP_stop_at_last_layers」を追加設定することで利用可能になる。(UIの再読み込みも必要)
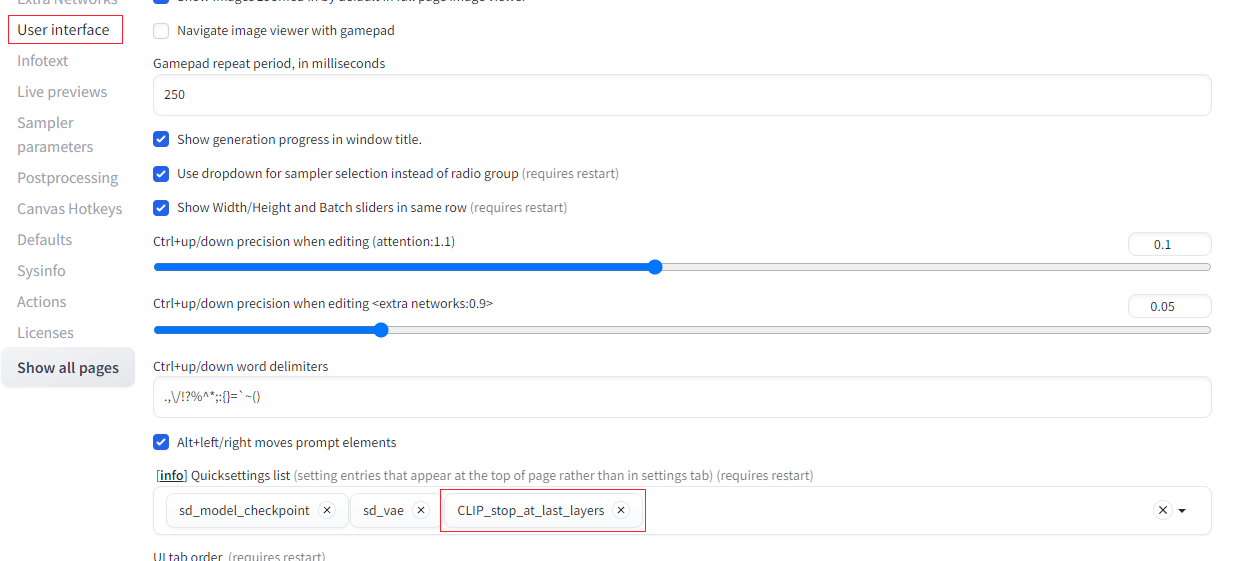
Clip skip=1(デフォルト)ならば12層目の出力を使い、Clip skip=2ならば11層目の出力を利用する。
それ以上の値を指定することも可能。
多くの公開されている学習済みモデルは学習に利用したClip skipの値が公表されているので、同じ値を使うと良い。
例えば上記のRealistic Visionでは、Civitaiのページに「CLIP SKIP: 1」という指定が記載されている。

Clip skipを変化させた出力の例
Hires. fix
Sampling methodの下にあるHires. fixにチェックを入れることで、出力画像の高画質化の設定項目を表示することができる。Hires. fixを有効にした場合、Stable Diffusionが出力した画像はUpscalerで指定したアルゴリズムorモデルによって拡大され、次にimg2imgで細部が描き込まれる。
Stable Diffusionは512x512あるいは768x768の画像で学習されているので、それより大きいサイズの画像を生成しようとすると破綻が起きやすい。そこで、512や768のサイズで一旦画像を生成し、img2imgで高画質化するという方法を取ることで破綻を防ぎながら大きいサイズの画像を生成することができる。
通常の生成を行った後にimg2imgを行うので、処理時間が通常より多くかかることに注意。

1305x1305で生成した画像

768x768で生成してからHires. fixで1.7倍に拡大した画像
Variations
Seedの右側にあるExtraにチェックを入れると、Variationの設定項目が表示される。その設定項目にSeedや強度を指定することで、元の出力画像とは微妙に異なる画像を出力することができるようになる。
例えば、全体的に理想の画像が出力されたものの一部の細かい部分(手の指など)にだけ不満があるような場合にこの機能を利用する。Seedや強度の組み合わせで大量のバリエーションを作ると、問題の箇所が綺麗に描画された画像がその中に含まれている可能性がある。

Variationsの例
出力設定の確認 (PNG Info)
AUTOMATIC1111で生成したpngファイルは、バイナリーデータの中に生成に用いられた設定値の情報が埋め込まれている。

バイナリーデータの中に埋め込まれた設定値
これらの情報は、AUTOMATIC1111のPNG Infoタブでも表示することができる。
インターネット上で共有された他の人の生成結果を読み込むことで、promptや設定値の工夫を学ぶことができる。
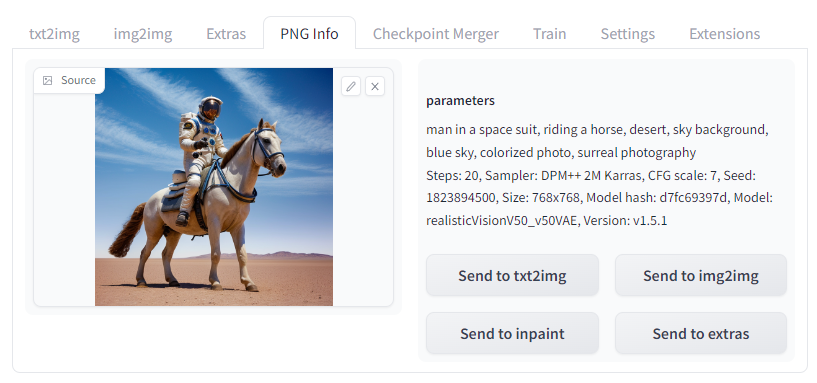
PNG Infoの画面
また、txt2imgやimg2imgのタブでPromptの欄に画像をドラッグアンドドロップすることでも設定を読み込むことができる。更にGenerateボタンの下にある「↙」のボタンを押すと、読み込んだ設定値を各欄に自動で反映させることができる。
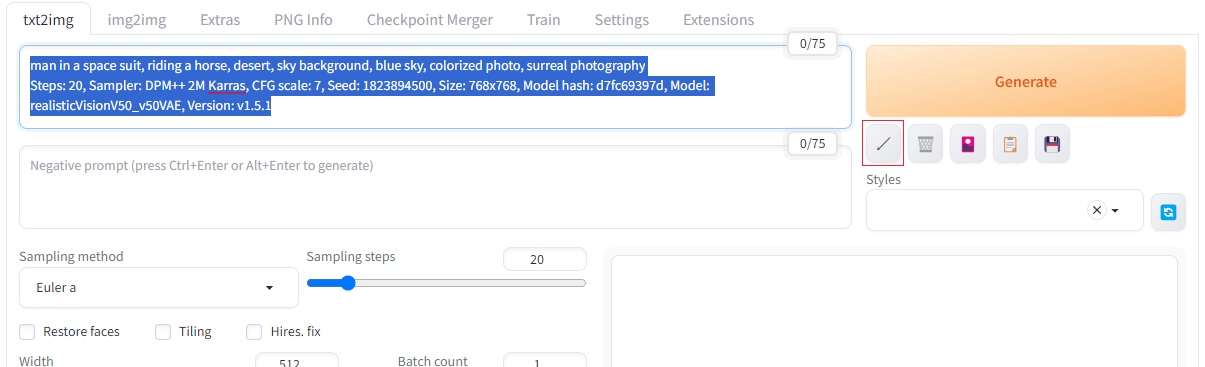
txt2imgの画面
出力設定の比較 (X/Y/Z plot)
X/Y/Z plotの機能を使うことで、設定値を変化させた比較表を1枚の画像に出力することができる。
以下の図は、Sampler(=Sampling method)とSteps(=Sampling steps)を変化させた比較の出力結果。
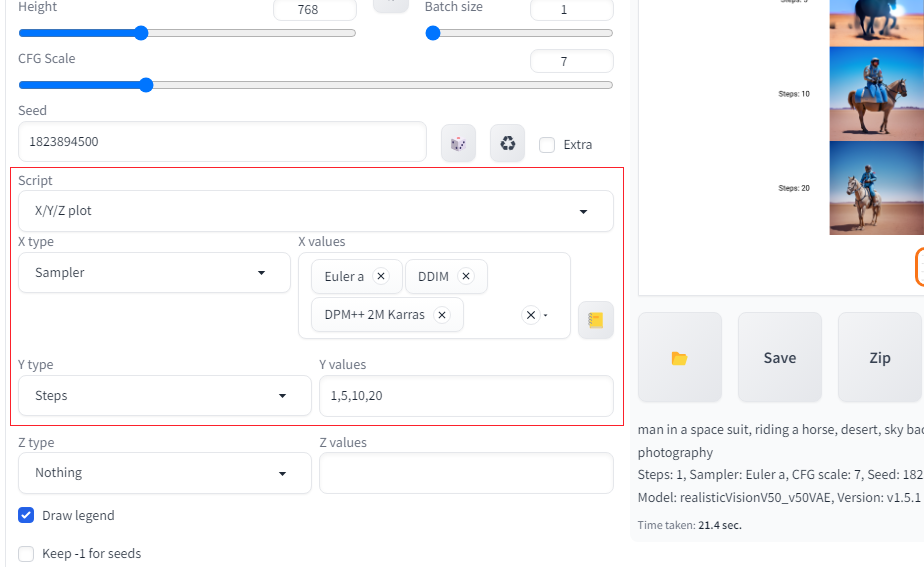
X/Y/Z plot の画面

X/Y/Z plot
拡張機能
AUTOMATIC1111は利用者によって様々な拡張機能が開発されている。
それらの拡張機能はExtensionsタブからインストールすることが可能。基本的にはGitのURLを入力すればインストールできるものが多いが、個々の導入方法は制作者のガイドに従うと良い。
参考
- Features · AUTOMATIC1111/stable-diffusion-webui Wiki · GitHub
- Negative prompt · AUTOMATIC1111/stable-diffusion-webui Wiki · GitHub
- stable-diffusion/scripts/img2img.py at main · CompVis/stable-diffusion · GitHub
- NovelAI Improvements on Stable Diffusion | by NovelAI | Medium