[Stable Diffusion] 追加学習の理論
この記事では、Stable Diffusion (SD)の様々な追加学習方式とその仕組みを解説する。
関連記事
目次
追加学習方式の分類
SDを追加学習するために多様な方式が考案されたが、それらのアイデアは大きく「モデル設計(PEFT)」と「損失設計」の工夫に分類することができる。
以下に紹介する「TI」「HN」「LoRA」はモデル設計で、「DB」・「ESD」(・「FT」)は損失設計に分類される。モデル設計と損失設計は互いに組み合わせて使用することができる。
| 追加パラメーター\損失 | FT | DB | ESD |
|---|---|---|---|
| なし | FT | DB | ESD |
| 疑似単語埋め込み | TI | DB-TI | - |
| HN | HN | ||
| LoRA | FT-LoRA | DB-LoRA | LECO |
fine-tune (FT)
通常のfine-tune(微調整)。
Stable Diffusionの事前学習と同様の設定・損失関数で、追加データに対して学習を行う。

SDのfine-tune
Textual Inversion (TI)
Textual Inversion(TI)は、2022年8月にテルアビブ大学とNVIDIAから発表されたtxt2imgモデルの学習方法。
言葉で表現することの難しい概念や個人を学習させるため、その概念に対応する新しい単語を追加するというアイデア。
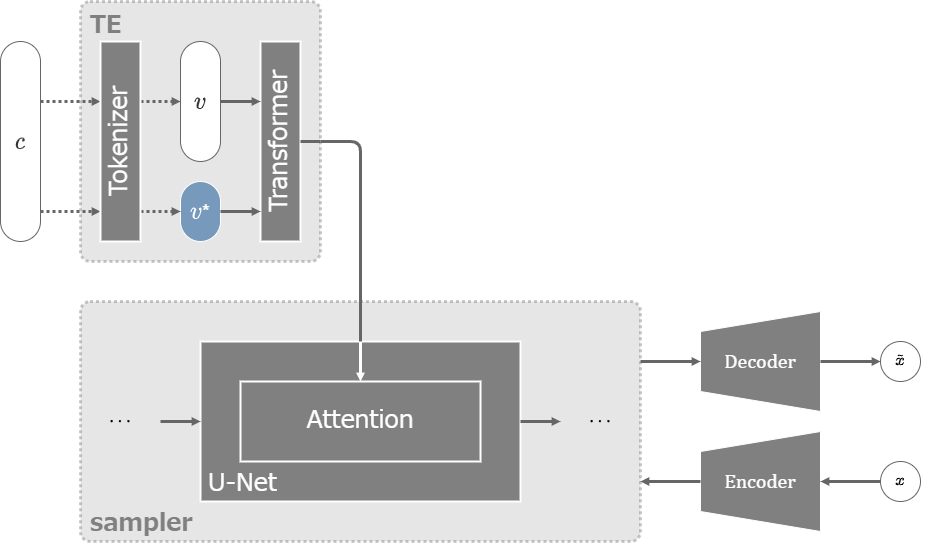
SDのTextual Inversion
学習したい新しい概念のために、専用の新しいトークン\(S^*\)とそれに対応する学習可能な埋め込みベクトル\(v^*\)を用意し、埋め込みベクトルだけを学習する。
3~5枚の画像だけでも十分学習できることが実験で確認されている。
DreamBooth (DB)
DreamBooth(DB)は、2022年8月にGoogleから発表されたtext2imgモデルの学習方法。
元々はGoogleの画像生成モデル「Imagen」のために考案された方法。
TIと似ているが、こちらはText Encoderの辞書から使用率の低い単語[V]を選択し、新しい概念で上書きする。
学習対象はU-Net全体とText Encoder全体。

SDのDreamBooth
まずは辞書から使用率の低い単語[V]を選択する。(例えば「shs」「sts」など)
選択した単語[V]は論文ではRare-token Identifier(あるいは単にIdentifier)と呼ばれる。(「Instance Token」「Trigger Word」などとも呼ばれる。)
学習対象の画像には予めクラス名[Class]を用意し、「A [V] [Class]」という文章で学習する。
例えば学習対象が特定の犬(個体)である場合、[Class]=dogとし、(例えば)「A shs dog」という文章で学習する。
しかし、これでは学習対象となる特定の概念と[Class]という単語との結びつきが強くなりすぎて、[Class]を含むpromptが学習対象だけを出力するような状況に陥ってしまう。(単語[V]を含まない場合でも、dogという単語を含むpromptが「学習対象の犬」ばかり出力するようになるなど)
そこでこのようなクラスの汚染を防ぐため、(凍結した)拡散モデルに「A [Class]」と入力して出力された画像を、再び「A [Class]」の文章と共に学習する損失項を追加する。このようにすることで、モデルが本来出力するべき[Class]の出力像を忘れないようにする効果が期待される。
クラスの汚染を防ぐために拡散モデル自身から出力された画像は正則化画像と呼ばれる。学習時に2つの拡散モデルを用意して、凍結した片方から正則化画像を逐次生成することもできるが、学習前に予め生成しておく方が効率的である。
最終的な損失関数は以下のようになる。
\begin{align} Loss = \mathbb{E}\left(w_t\|x_\theta(A\;[V]\;[Class])-x\|^2\right) + \lambda \mathbb{E}\left(w_t\|x_\theta(A\;[Class])-x_{reg}\|^2\right) \end{align}
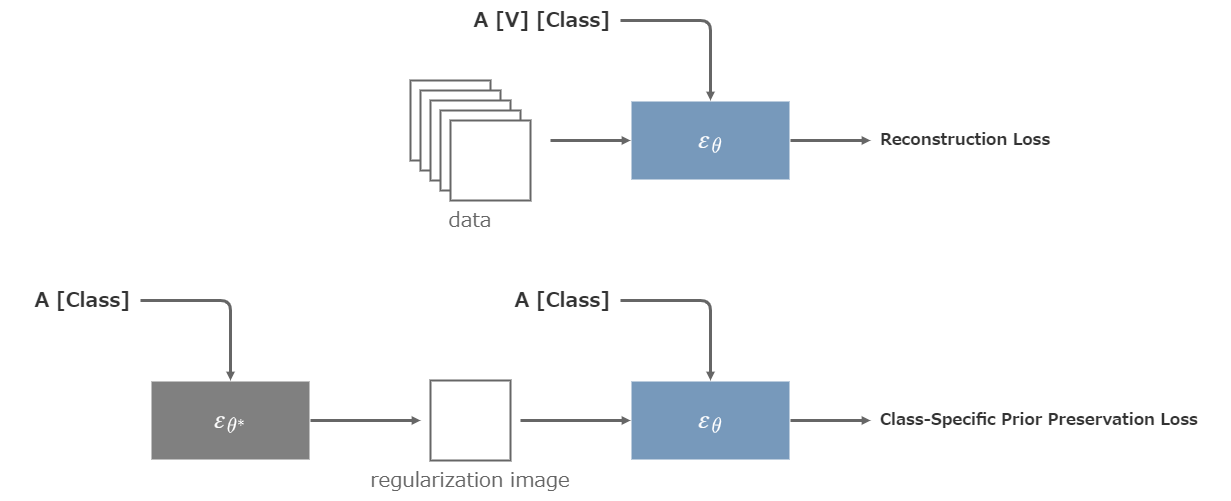
DreamBoothの学習。\(\theta^\ast\)は凍結されたU-Netで、\(\theta\)は学習対象のU-Net。
TIと同じく、3~5枚の画像だけでも十分学習できることが実験で確認されている。
Hypernetworks (HN)
Hypernetworks(HN)はNobelAIの開発チームに所属するKurumuz氏が2021年に考案し、2022年秋に発表した学習方法。
U-NetのCross-AttentionでKとVを生成する層の直後に層を追加し、追加した層だけを学習する。追加層の具体的な設計は実装によって様々。
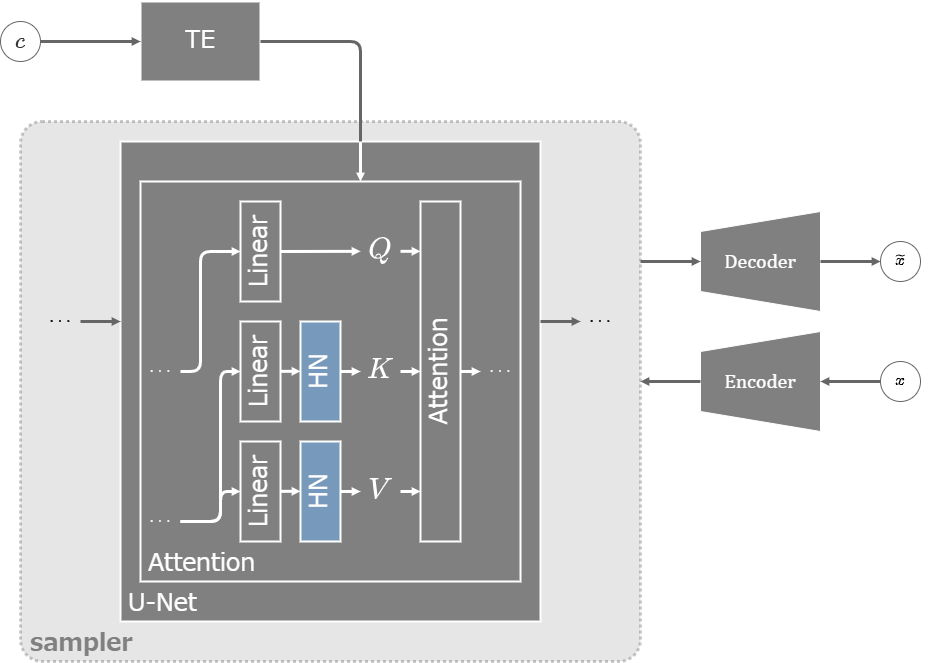
SDのHypernetworks
AUTOMATIC1111のHN
AUTOMATIC1111では、Linear層・活性関数などを選択してHypernetworksを自由に作ることができる。(modules.hypernetworks.hypernetwork.HypernetworkModule)
Train→Create hypernetworkの画面で設定する。
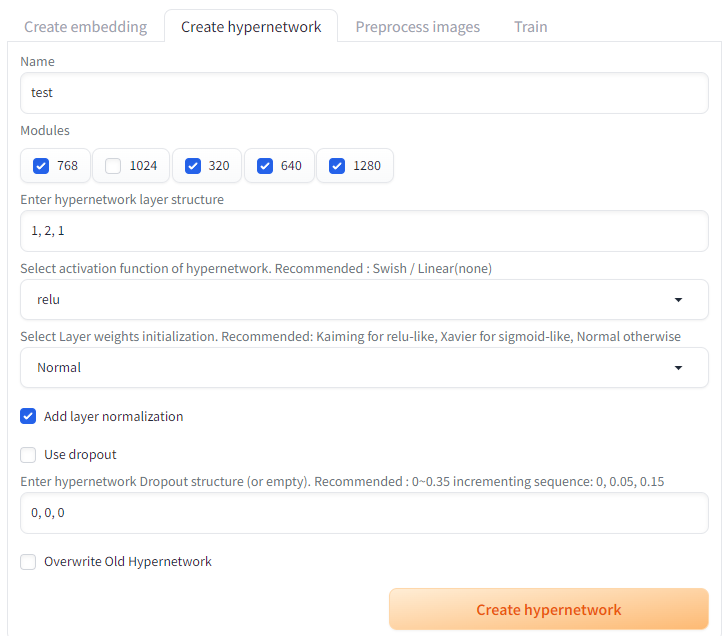
AUTOMATIC1111でHypernetworksを追加する設定画面
- layer structure - Linear層の次元を設定する。例えば1, 2, 1の場合は、最初のLinear層で次元が1倍から2倍になり、次のLinear層で次元が2倍から1倍になる。最初と最後は必ず1でなければならない。
- activation function - linear以外を選択するとLinear層の後に活性化関数が適用される。ただし、最後のLinaer層の後には追加されない。
- layer normalization - チェックを入れると活性化関数の後にLayerNormが適用される。
- Dropout - Use dropoutにチェックを入れた上で0より大きい値を設定すると、設定した割合のDropoutが有効になりLayerNormの後に適用される。最初の数字は使われず、2つ目以降の値が使われる。
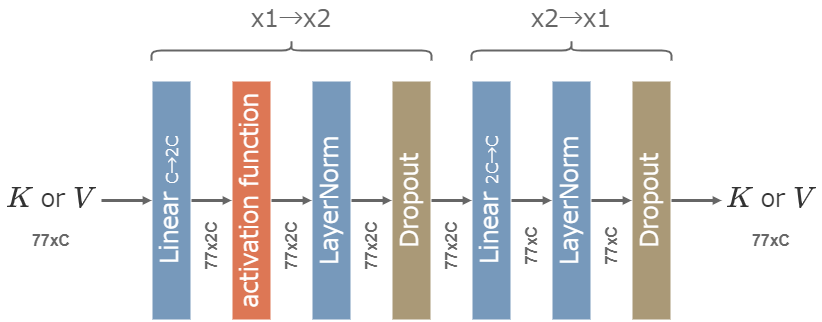
AUTOMATIC1111のHypernetworksの構造 (layer structure = 1, 2, 1の場合)
SDでは個々のAttentionブロックによって扱う次元が異なる(C=320, 640, 1280)。Hypernetwoksはその次元の種類の分だけ用意され、同じ次元のK、同じ次元のVでそれぞれパラメーターが共有される。つまりSDの場合、(320, K), (320, V), (640, K), (640, V), (1280, K), (1280, V)の6種類のパラメーターが作られ、異なるAttention同士で共有される。
AUTOMATIC1111の実装では、HypernetworksをCross-AttentionだけでなくSelf-Attentionにも適用する。この適用はTEにも及ぶので、上記の6種類に加えて(768, K), (786, V)の2種類のパラメーターも作られる。
(IA)³
Infused Adapter by Inhibiting and Amplifying Inner Activations((IA)³)は、2022年5月に発表された学習方法。
HyperNetworksと同じようにCross-Attention部分にパラメーターを追加するのだが、(IA)³は次元と同じサイズの1列のパラメーターと成分ごとの積を取るだけで、追加されるパラメーター数が非常に少ない。
Cross-Attention部分だけでなく、TransformerのFeed Forward部分にもパラメーターが追加される。
異なる層でパラメーターを共有するHypernetworksとは異なり、(IA)³ではパラメーターの共有は行われない。

(IA)³
Low-Rank Adaptation (LoRA)
LoRA
LoRAは、2021年6月にMicrosoftから発表されたLLM(大規模言語モデル)の学習を効率化するための技術。
大規模なモデルをfine-tuneするために全てのパラメーターを学習するのはコストが大きすぎるので、パラメーターを直接学習する代わりに更新の差分だけを学習するというアイデア。
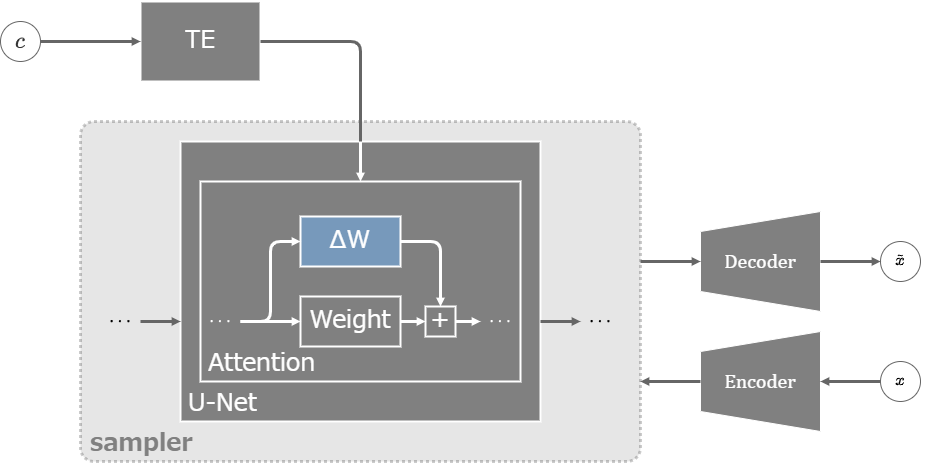
SDのLoRA(LoRA-LierLa)
元のパラメーター\(W\)は凍結し、差分に該当する学習可能な行列\(\Delta W\)を並列で接続する。\(\Delta W\)は2つの行列の積\(\Delta W=BA\)で表され、行列\(B\)の各成分は学習初期に0で初期化される。
\(W\in R^{d\times k}\)であるとき、\(B\in R^{d\times r}, A\in R^{r\times k}\)とすると\(\Delta W=BA\)のパラメーター数は\(r(d+k)\)となる。\(r<\min(d,k)/2\)のとき\(r(d+k)<dk\)となるので、\(W\)より学習すべきパラメーター数が削減されることがわかる。
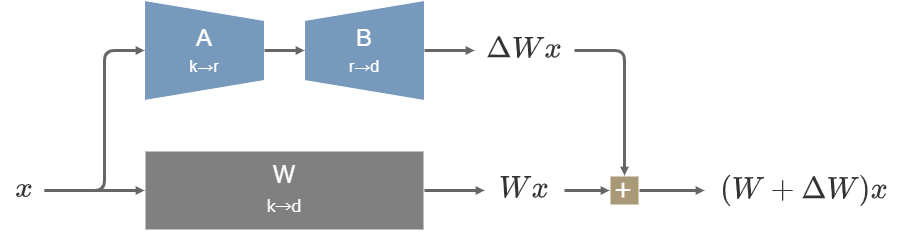
LoRAの構造
行列を2つに分割したことで\(\Delta W=BA\)のランク(階数)の上限は\(\min(d,k)\)から\(r\)に下がるが、GPT-3で行った実験によると\(r\)を1や2などの極端に小さな値としても十分な表現力が保てることが示されている。(Stable Diffutionでは\(r\)は4~128程度の値が選択されることが多い模様)
LoRAの特徴は以下:
- 通常のfine-tune (Full fine-tune)より大幅に少ないパラメーターで学習するので、計算コストを低く抑えられる。
- 行列\(B\)は0で初期化されるので、学習初期では\((W+\Delta W)x=Wx\)となって、元のモデルと全く同じ動作となる。これにより学習が安定する。
- LoRAは分岐してから統合されるまでの経路に非線形関数を含まないので、十分な学習を行った後に\(\Delta W\)の各成分を\(W\)に加算することでマージすることができる。マージすることにより、元のモデルと同じ計算量で推論することができるようになる。(推論レイテンシーが追加されない)
- 必要に応じてLoRAを付け替えるという操作も可能となり、元のモデルを様々なタスクに流用しやすい。複数のLoRAを組み合わせて適用することも仕組みとして可能。
LoRA自体は学習対象となるパラメーターをどのように設計するかという理論でしかないので、DreamBoothのようなIdentifierを用いた学習方法と両立させることもできる。
LoHa
LoHa(LoRA with Hadamard Product representation)では、LoRAの行列を2つに分割し、両者の要素ごとの積を取るという仕組みが用いられる。2021年8月に公開された韓国の浦項工科大学校の論文に基づいた技術。
\(r\)を2倍に増やしたとき行列のランクの上限は\(2r\)になるが、以下の図のように同じ形の行列\(D,C\)を作り要素ごとの積を取ると、同じパラメーター数でも行列のランクの上限は\(r^2\)になる。
この仕組みにより同じパラメーター数でLoRA行列のランクを上げる、あるいはLoRA行列のランクを保ちながらパラメーター数を削減することが可能となる。

LoHaの構造
SDへの適用は2023年3月9日にKohaku-Blueleaf氏によって公開された。(同時にLoConやLoHaはLyCORISという一つのプロジェクトにまとめられた)
その他に、Kronecker積を取って更にパラメーター数を削減するLoKrなども考案されている。
SDへの適用 (LoRA-LierLa, LoCon)
LoRA-LierLa
LoRAのStable Diffusionへの適用は2022年12月7日のSimo Ryu氏(cloneofsimo)による実装が最初。その後、2022年12月18日にKohya S.氏(kohya-ss)もまたStable Diffusion用のLoRAを実装し、現在はKohya氏のLoRAが主流になっている。
最初の実装では、U-NetのAttentionブロックに含まれるLinear層とConv1x1層へのみ適用された。Kohya氏はこのLoRAをLoRA-LierLa (LoRA for Linear Layers, LoRAリエラ)と名付けている。
LoCon
LoCon(LoRA for Convolutional Network)では、LoRAの構造をLinear層や1x1の畳み込み層だけでなく、3x3の畳み込み層にまで適用できるように改変した。具体的には、3x3の畳み込み層で次元をrに下げ、その後1x1の畳み込み層で変換後の次元へ戻す。
3x3の畳み込みにLoRAの構造を適用できるようになったことで、LoRAの適用範囲をAttentionブロックだけでなく、これまで学習対象としていなかったResブロックやその他全ての層にまで広げることが可能になった。
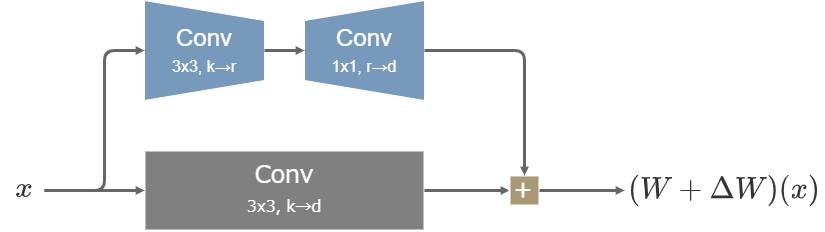
LoConの構造
3x3の畳み込み層への適用はcloneofsimo氏が最初に実装し、その後2023年2月27日にKohaku-Blueleaf氏(KohakuBlueleaf)がResブロックへの適用をLoConと名付けて公開した。Kohya氏はこのLoRAをLoRA-C3Lier (LoRA for Colutional layers with 3x3 Kernel and Linear layers, LoRAセリア)と名付けている。
LoRAの凍結 (LoRA-FA, VeRA)
LoRAの適用に加えて、更にLoRAの一部のパラメーターを凍結する(=学習しないようにする)ことで、更に学習を効率化する方法も研究されている。
LoRA-FA
2023年8月に発表されたLoRA-FA(LoRA with Frozen-A)では、LoRAの2つの行列の内Aを凍結してBだけを学習する。
Aはランダムに初期化されてから、学習中には値が一切変動しない。
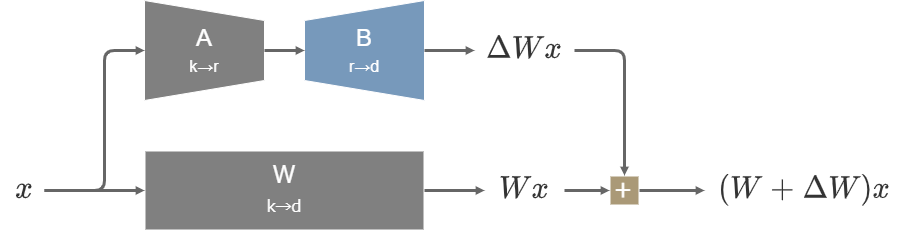
LoRA-FAの構造
VeRA
2023年10月に発表されたVeRA(Vector-based Random Matrix Adaptation)では、LoRAよりも更に細かく\(\Delta W=vBuA\)と分解する。
BとAはモデル全体の全ての同じサイズの層で値が共有される構造となっていて、初期化されてから凍結される。
vとuは対角行列(ベクトルv, uと要素ごとの積を取るのと同じこと)であり学習の対象となる。
BとAがモデル全体で共有されることで追加パラメーターの総数が大幅に削減され、推論時にもメモリ効率が高くなる利点がある。
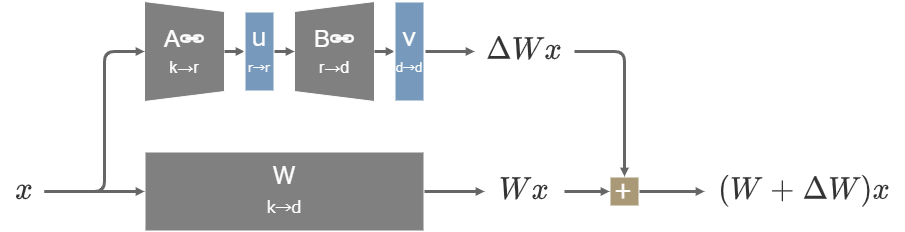
VeRAの構造
また、より一般にv, B, u, Aのどの層を凍結するかということについて、NVIDIAは2023年11月のTied-LoRAという論文で研究している。全ての層を学習対象にした場合でもパラメーター共有の効果によって追加パラメーター数を大幅に減らすことができ、しかもLoRAと同程度の性能を維持できるという実験結果が示されている。
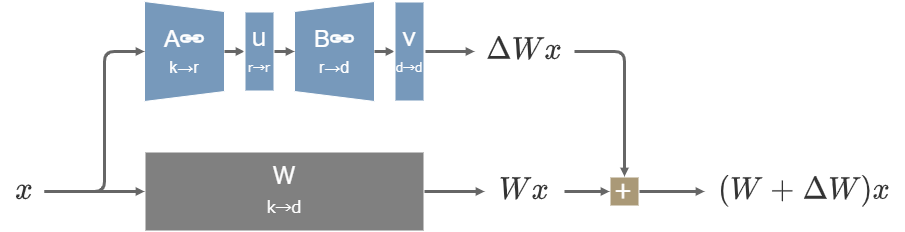
Tied-LoRAの構造 (全ての層を学習する場合)
LECO
LECO(Low-rank adaptation for Erasing COncepts from diffusion models)はLoRA(LoRA-LierLa)やLoConを使ってSDから特定の概念を忘れさせる学習方法。LECOで学習することで、特定の条件の画像(著作権で保護された画像やNSFWコンテンツなど)をSDが出力しないようにすることができる。
ノースイースタン大学とマサチューセッツ工科大学が2023年3月に論文で公開したESD(Erased Stable Diffusion)という理論に基づく。Plat氏(p1atdev)が2023年6月29日に公開したLECOの実装では、この理論をLoRAに適用することで学習を容易にした。
学習のための画像データが1枚も必要ないことも特徴。
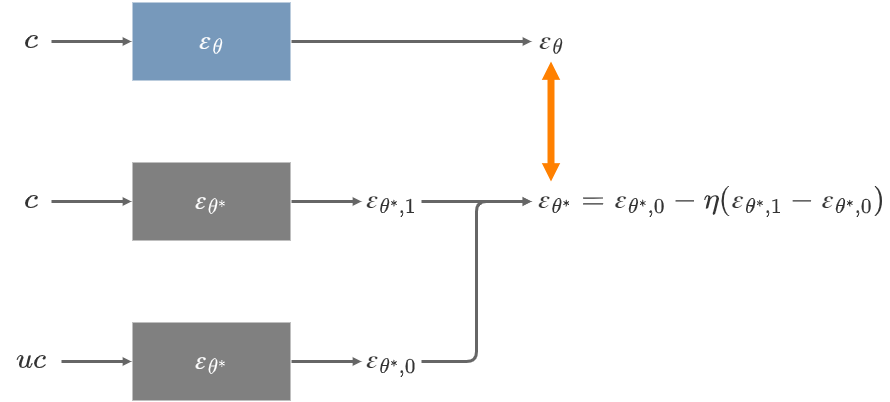
LECOの学習
LECOでは、学習対象のSDとパラメーターを凍結したSDを用いる。前者のパラメーターを\(\theta\)、後者のパラメーターを\(\theta^*\)と表す。
忘れさせたい概念に対応するpromptを\(c\)とする。
凍結したSDを使って次の値を計算する。この値は負のCFG scaleが作用した値と見ることができる。
\begin{align} \varepsilon_{\theta^*}(x_t,t) -\eta \left( \varepsilon_{\theta^*}(x_t,t,c) - \varepsilon_{\theta^*}(x_t,t) \right) \end{align}
学習対象のSDからはprompt \(c\)で出力した値を出力させる。
\begin{align} \varepsilon_{\theta}(x_t,t,c) \end{align}
これらの値の\(L^2\)距離が近くなるように学習する。このように学習することで、prompt \(c\)を入力したときに生成画像はむしろ\(c\)から遠ざかるようになる。
\begin{align} Loss &= \| \varepsilon_{\theta}(x_t,t,c) - \left( \varepsilon_{\theta^*}(x_t,t) -\eta \left( \varepsilon_{\theta^*}(x_t,t,c) - \varepsilon_{\theta^*}(x_t,t) \right) \right) \|^2 \\ &= \| P - \left( N^* -\eta \left( P^* - N^* \right) \right) \|^2 \\ \end{align}
この理論の当初の目的は概念を忘れさせることだったが、逆に\(\eta\)に負の値を取る(つまり通常のCFGを学習する)ことで、特定の概念を強調するように学習することもできる。LECOでは忘れさせる学習をerase、強調させる学習をenhanceと呼び、両方の機能が用意されている。
また、元の理論では学習時のucに空文字を入れることを想定しているが、LECOではucにNegative promptを入れることも可能。
参考
Textual Inversion
- An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
- [2208.01618] An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
- AI を自分好みに調整できる、追加学習まとめ (その2 : Textual Inversion )|teftef
DreamBooth
- DreamBooth
- [2208.12242] DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
- AI を自分好みに調整できる、追加学習まとめ ( その3 : DreamBooth )|teftef
Hypernetworks
- NovelAI Improvements on Stable Diffusion | by NovelAI | Medium
- Hypernetwork training · AUTOMATIC1111/stable-diffusion-webui · Discussion #2284 · GitHub
- [Diffusion Model] Hypernetworksのレイヤー構造を変えた際の変化を比較する
(IA)³
- [2205.05638] Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning
LoRA
- [2106.09685] LoRA: Low-Rank Adaptation of Large Language Models
- [2310.11454] VeRA: Vector-based Random Matrix Adaptation
- [2308.03303] LoRA-FA: Memory-efficient Low-rank Adaptation for Large Language Models Fine-tuning
- [2311.09578] Tied-Lora: Enhacing parameter efficiency of LoRA with weight tying
- [輪講資料] LoRA: Low-Rank Adaptation of Large Language Models - Speaker Deck
- Stable Diffusion、UNetのすべて|gcem156
LoRA-LierLa
- GitHub - cloneofsimo/lora: Using Low-rank adaptation to quickly fine-tune diffusion models.
- sd-scripts/docs/train_network_README-ja.md at main · kohya-ss/sd-scripts · GitHub (LoRA-LierLa)
LyCORIS
- [2108.06098] FedPara: Low-Rank Hadamard Product for Communication-Efficient Federated Learning
- GitHub - KohakuBlueleaf/LyCORIS: Lora beYond Conventional methods, Other Rank adaptation Implementations for Stable diffusion. (LoCon, LoHa, LoKR)