[Stable Diffusion] SDXL
この記事では2023年6月22日に公開されたSD (Stable Diffusion)のの強化版「SDXL」について解説する。
関連記事
目次
モデル構造
SDXLでは画像をBaseとRefinerの2段階の拡散過程で生成する。
Baseではこれまでと同様に完全なノイズから画像を生成し、RefinerではBaseで生成した画像(の潜在ベクトル)を元にimg2img (=noising-denoising process)を行うことで生成画像の品質を向上させる働きを担う。
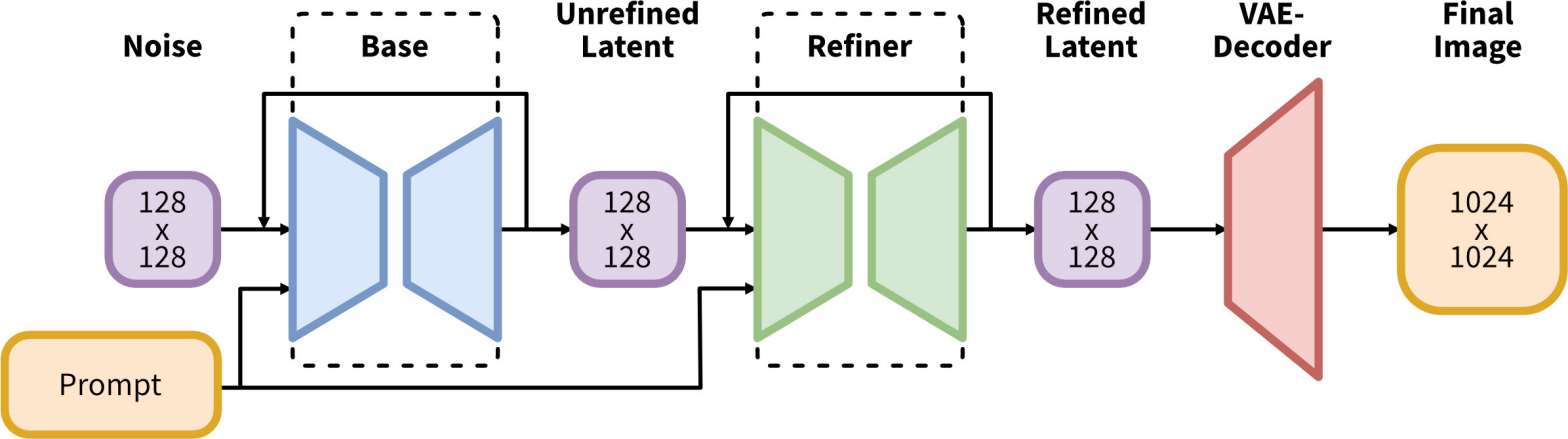
BaseとRefiner (SDXLの論文から引用)
Baseで画像を生成した後にRefinerでimg2imgを行うということは、Baseの生成途中でRefinerに切り替えることとほとんど同じ。AUTOMATIC1111ではそのように実装されている模様。
U-Net
U-NetはBaseとRefinerでそれぞれ異なる構造を持つ。
SDのU-Netと比べると、層の次元・U-Netの深さ・Attentionの個数(=depth、後述)が調整されている。
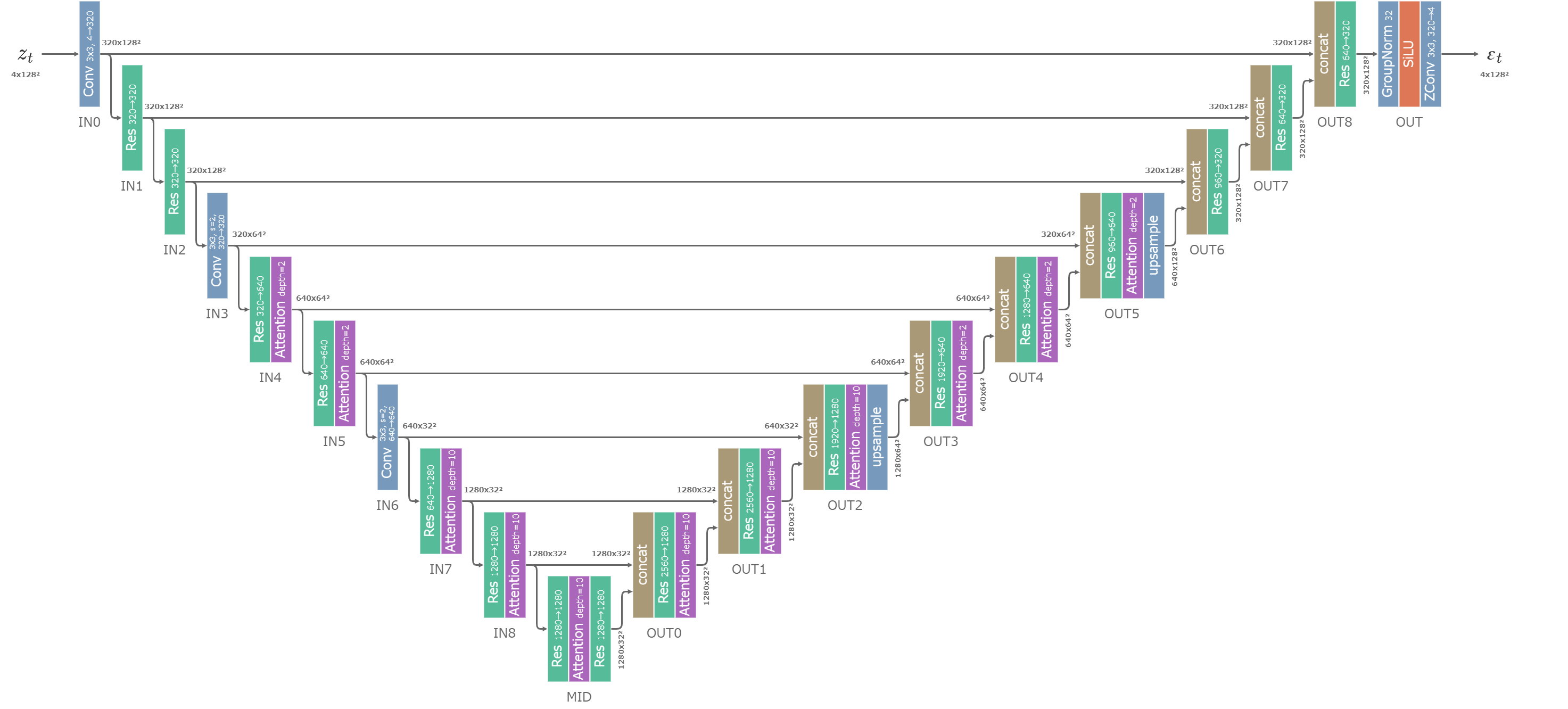
BaseのU-Net (クリックで拡大)
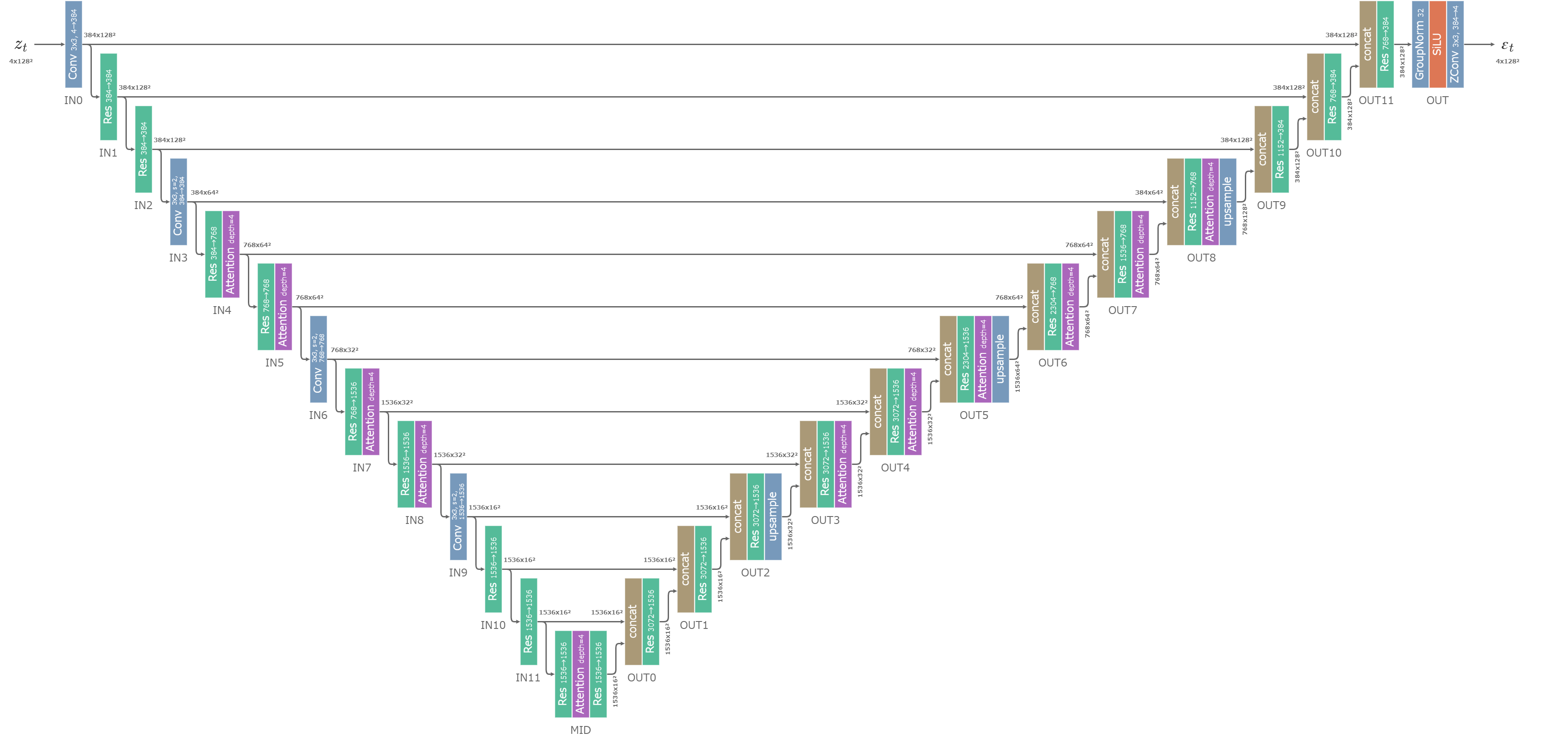
RefinerのU-Net (クリックで拡大)
AttentionBlock
SDでは1つのAttentionBlockに含まれるTransformerは必ず1つだけだったが、SDXLでは複数のTransformerを含む。
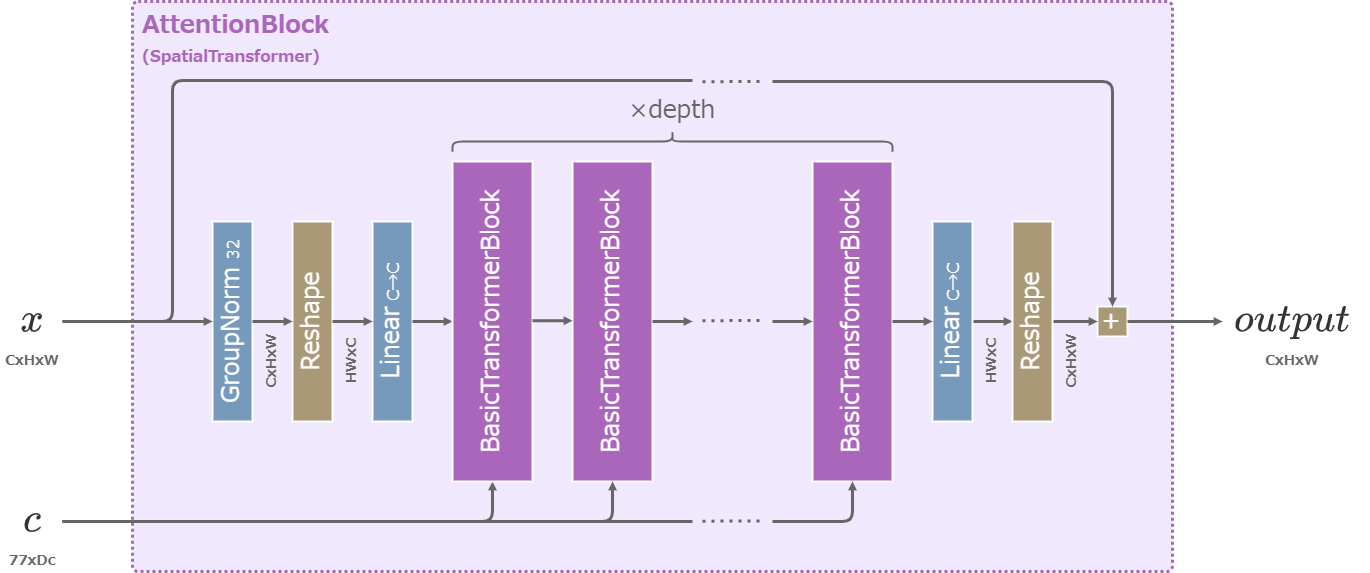
複数のTransformerを含むAttentionBlock
また、SDではTransformerのheadの数は常に8だったが、SDXLでは分割後の次元が64になるような値が用いられる。
例えば入力次元が1536の場合、\(head=1536/64=24\)となる。
SDXLのTransformer
Conditioner
SDではU-Netに条件値としてPromptとTimestepを与えていたが、SDXLでは更に画像の切り取り(crop)に関する情報を追加条件として与えて学習している。
また、Refinerでは画像の美的スコアも条件として与える。
| 項目 | 形式 | 学習時 | 推論時 | Base | Refiner | 作用する対象 |
|---|---|---|---|---|---|---|
| txt (Promptと同じ) | 英語の文章 | 画像のPrompt | Prompt | ○ | ○ | Attn・Res |
| original_size_as_tuple | \(c_{size}\)=(height, width) | 元の画像サイズ | 出力サイズ | ○ | ○ | Res |
| crop_coords_top_left | \(c_{crop}\)=(top, left) | crop位置 | (0,0) | ○ | ○ | Res |
| target_size_as_tuple | \(c_{ar}\)=(height, width) | 入力画像サイズ | 出力サイズ | ○ | - | Res |
| aesthetic_score | 1次元の値\(\in [0,10]\) | 画像の美的スコア | positive: 6.0 negative: 2.5 |
- | ○ | Res |
条件入力は以下の図のように処理される。
出力される値の内、crossattnはAttentionBlockのCross-Attentionに利用され、vectorは最終的にSDにも存在したTimestep埋め込みと加算されてResBlockに利用される。
また、SDXLではText Encoderの出力の一部がvector側にも流入し、ResBlockに影響を及ぼす。(Stable DiffusionではPromptはAttentionBlockにのみ作用していた)

Baseの条件入力

Refinerの条件入力
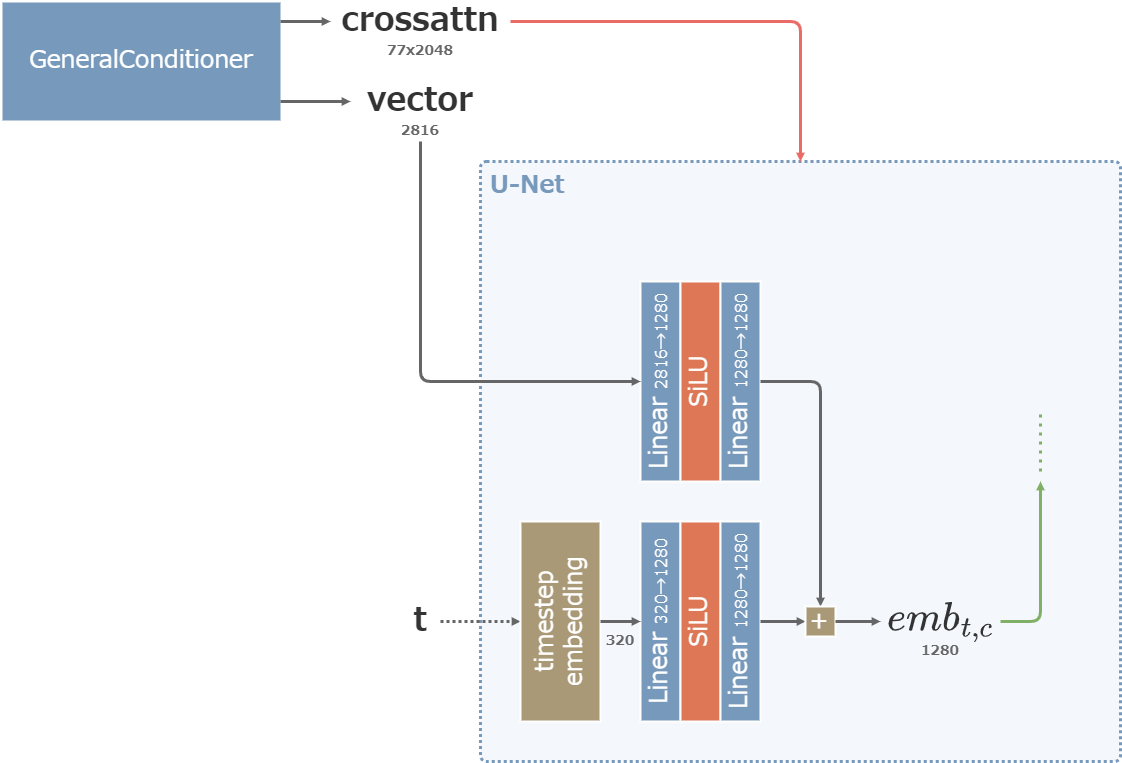
条件値vectorとTimestepの統合 (図中の数値はBaseの場合のもの)
ConcatTimestepEmbedderNDは、SDのtimestep_embeddingと同一のもの。
出力次元は320ではなく256が採用される。入力が2次元の場合はそれぞれ処理した結果を縦にconcatして512次元で出力する。
\begin{align} ConcatTimestepEmbedderND(x) := \begin{pmatrix} \cos(x\cdot 10000^{-\frac{0}{128}}) \\ \vdots \\ \cos(x\cdot 10000^{-\frac{127}{128}}) \\ \sin(x\cdot 10000^{-\frac{0}{128}}) \\ \vdots \\ \sin(x\cdot 10000^{-\frac{127}{128}}) \\ \end{pmatrix} \end{align}
\begin{align} ConcatTimestepEmbedderND(x, y) := \begin{pmatrix} \cos(x\cdot 10000^{-\frac{0}{128}}) \\ \vdots \\ \cos(x\cdot 10000^{-\frac{127}{128}}) \\ \sin(x\cdot 10000^{-\frac{0}{128}}) \\ \vdots \\ \sin(x\cdot 10000^{-\frac{127}{128}}) \\ \cos(y\cdot 10000^{-\frac{0}{128}}) \\ \vdots \\ \cos(y\cdot 10000^{-\frac{127}{128}}) \\ \sin(y\cdot 10000^{-\frac{0}{128}}) \\ \vdots \\ \sin(y\cdot 10000^{-\frac{127}{128}}) \\ \end{pmatrix} \end{align}
Text Encoder (CLIP)
上図のように、SDXLのText Encoderは2種類存在する。
CLIP ViT-L
片方はSDで使われたものと同一のCLIP。
SDXLでは、CLIP skip=2が適用される。ただし、AUTOMATIC1111の従来の実装とは異なり、SDXLではskip後にLayerNormを通らない。
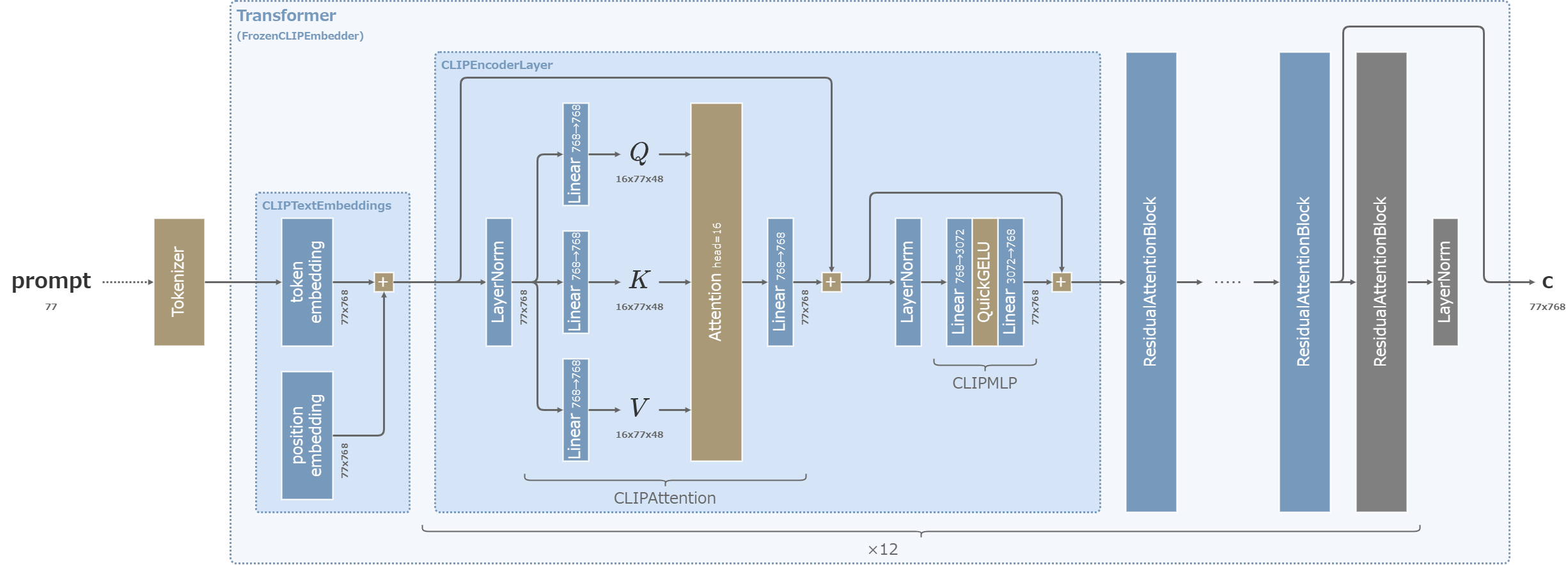
SDXLのCLIP ViT-L (クリックで拡大)
OpenCLIP ViT-bigG
もう片方はより大きな1280次元で学習したCLIP。
前者のCLIPと同様に、CLIP skip=2の値を利用する。
また、LayerNormを通った77x1280の値から、EOTトークン(End of Text=文章の末尾)の位置の1280次元のベクトルだけを取り出し、ResBlockで利用するための出力とする。
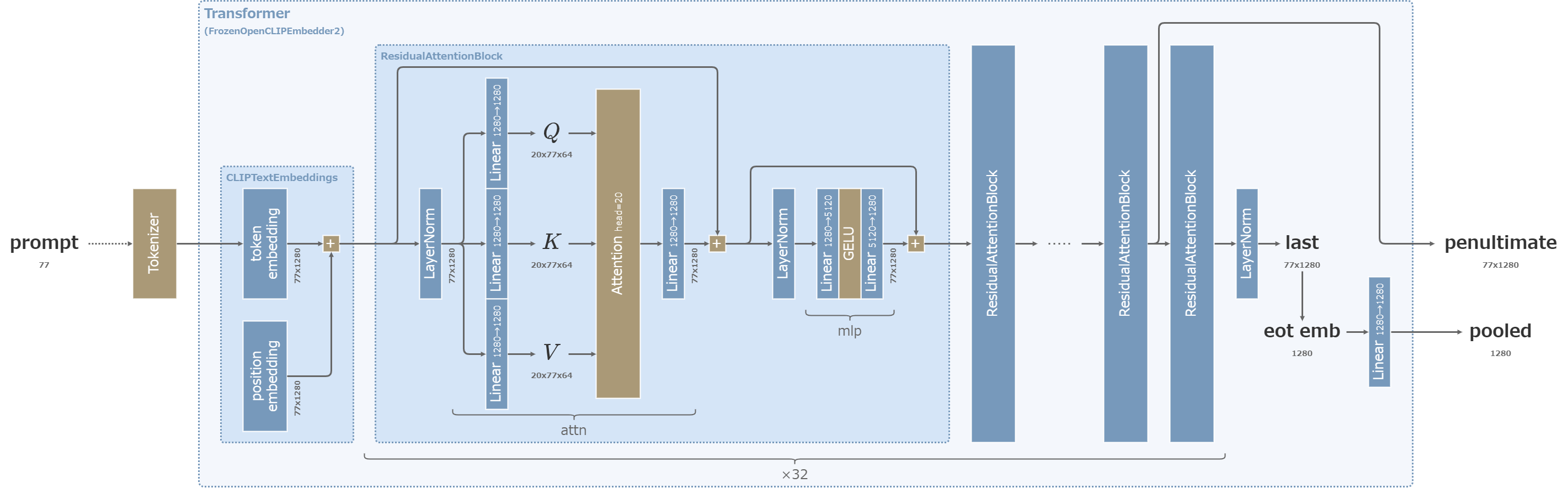
SDXLのOpenCLIP ViT-bigG (クリックで拡大)
学習
SDXLではモデル構造を変化させただけでなく、学習にも様々なテクニックを取り入れている。
Multi-Aspect Training
画像生成モデルの教師データセットには多様なサイズ・アスペクト比の画像が含まれるが、GPU計算の仕組み上、入力される画像のサイズはバッチ内で揃っていなければならない。
そのため、SDでは入力画像のアスペクト比にかかわらず画像を正方形に切り取って学習に利用していた。
しかし、そのせいで例えば人が写った縦長の画像では顔や足が切れた状態で学習に利用されることが多くなり、その結果として生成時にも同様の画像が生成されやすくなるという問題が生じていた。

SD1.5で顔が切れた画像が生成される例 (SDXLの論文から引用)
SDXLではこの問題を緩和するため、モデル構造の節で説明したようにcrop位置・cropサイズを明示的にモデルに与えている。そうすることで、仮に顔が切れた画像が入力として与えられたとしても、モデルがその原因をcrop情報から認識できるような構造になっている。
更に、生成時にはcrop位置に(0,0)を指定し、cropサイズ(=入力サイズ)とオリジナルの画像サイズに同じ値を与えることで、顔が切れた画像が生成されにくくすることができるようになる。
Aspect Ratio Bucketing
一方、NovelAIではデータセットに含まれる複数のアスペクト比の画像を有効活用するために、独自にAspect Ratio Bucketingという仕組みを取り入れている。この手法は2022年10月11日にNovelAIブログで公開され、SDXLにも取り入れられている。
SDXLのAspect Ratio Bucketingでは、画素数が\(1024^2\)に近くなるような複数の画像サイズ(=Bucket)が以下のように用意され、データセットから取り出された画像はこれらの中から最も近いアスペクト比のBucketに収納される。そして、Bucketがバッチサイズ分溜まったときにモデルの学習に利用される。
(512, 2048) (512, 1984) (512, 1920) (512, 1856) (576, 1792) (576, 1728) (576, 1664) (640, 1600) (640, 1536) (704, 1472) (704, 1408) (704, 1344) (768, 1344) (768, 1280) (832, 1216) (832, 1152) (896, 1152) (896, 1088) (960, 1088) (960, 1024) (1024, 1024) (1024, 960) (1088, 960) (1088, 896) (1152, 896) (1152, 832) (1216, 832) (1280, 768) (1344, 768) (1344, 704) (1408, 704) (1472, 704) (1536, 640) (1600, 640) (1664, 576) (1728, 576) (1792, 576) (1856, 512) (1920, 512) (1984, 512) (2048, 512)
この仕組みはcropと両立することはできないが、SDXLではまずcropを用いて事前学習し、最後にAspect Ratio Bucketingを用いて微調整することで両方の仕組みを活用している。(後述)
Offset-Noise
拡散モデルは十分なタイムステップを経て元の画像を完全なノイズに変換する確率過程を前提としているが、元の画像が極端に明るかったり暗かったりする場合には1000回のタイムステップでは完全なノイズにはならない問題があることが知られるようになった。
その結果、生成過程では完全なノイズから画像を生成し始めるが、拡散過程で得られる不完全なノイズ画像との差異が、SDの画像生成に影響を及ぼすこととなる。例えば、以下のように明るい画像を生成しようとしても画面の一部に暗い領域が生じるなど、画像全体の画素値の平均が明るい方にも暗い方にも偏らないような挙動が確かめられた。

Offset-Noiseを用いずに学習した場合の生成例 (Offset-Noiseの解説ページから引用)
このような現象が起こる要因は以下のように説明できる。
拡散過程では画像(の潜在ベクトル)の各成分(=画素・チャンネル)に対して独立なノイズを加える。各成分のノイズが独立に\(\varepsilon_{i,j}\sim\mathcal{N}(0,1)\)から取り出されているとすると、正規分布の再生成によりノイズの全成分の平均は成分数を\(N\)としたときに次のようになる。
\begin{align} \sum_{i,j}\varepsilon_{i,j} &\sim \mathcal{N}(0,N) \\ \frac{1}{N}\sum_{i,j}\varepsilon_{i,j} &\sim \mathcal{N}(0,\frac{1}{N}) \\ \end{align}
したがって、成分数Nが多いほど画像全体の平均色(平均成分)の変動は反比例で遅くなるということがわかる。
その結果、例えば明るい画像を元に1000回分の拡散過程を実行したとしても、画像の平均色は依然としてやや明るい側に偏るということになる。生成過程の最初の段階で完全なノイズとしてサンプリングされた潜在ベクトルは平均の期待値が0(=灰色)となるので、生成過程を経ても明るい画像を生成することが困難となる。
その対策として考案されたのがOffset-Noiseである。この手法は2023年1月30日にNicholas Guttenbergによって発表された。
Offset-Noiseでは平均色の変動を促進するために、拡散過程において以下の式で表されるノイズを使用する。このノイズでは、従来の画素ごとのノイズだけでなく、画像全体で同じ値の一様なノイズ(=Offset-Noise)も加える。Guttenberg氏の例ではOffset-Noiseは0.1の重みで加えられているが、SDXLでは0.05の重みを使用する。
\begin{align} noise = randn(0,I) + 0.05\times randn(0,1) \end{align}
SDXLではN=4×128²=65536なので、Offset-Noiseによって画像の平均色の分散は1/N=0.000015から1/N+0.05²=0.002515に164.84倍に増大(標準偏差は12.839倍に増大)することになり、非常に大きな効果を持つことがわかる。
Offset-Noiseが拡散過程と生成過程に及ぼす影響を以下の図に表す。
左はOffset-Noiseがない場合で、右は0.05のOffset-Noiseを加えた場合。
平均色が\(0.9\in[-1,1]\)の画像の拡散過程を赤い領域で示す。領域は、各タイムステップにおける潜在ベクトルの平均色の2σ区間を表す。
また、完全なノイズからの生成過程を青い領域で示す。領域は、各タイムステップにおける潜在ベクトルの平均色の2σ区間を表す。(逆過程を求めるために必要となるデータセットの分布は、PASCAL VOCの全画像の平均色の統計を調べて正規分布を仮定することで擬似的に利用した)
Offset-Noiseがない場合、0.9という値の非常に明るい画像は1000ステップの拡散過程を経ても青い領域と重ならず、完全なノイズになっていないことがわかる。また、生成過程においても生成される画像の平均色の幅は狭い。
一方で、0.05のOffset-Noiseを加えた場合は、明るい画像も拡散過程を経て完全なノイズの領域と重なることがわかる。生成過程においてもOffset-Noiseがない場合と比べて多様な明るさの画像を生成できることがわかる。

Offset-Noiseが拡散過程と生成過程に及ぼす影響。左はOffset-Noise=0、右はOffset-Noise=0.05。
Guttenberg氏のSDでの実験では、Offset-Noiseを加えて学習することで、以下のように全体的に明るい画像や暗い画像も生成できるようになることが確かめられた。

Offset-Noiseを用いて学習した場合の生成例 (Offset-Noiseの解説ページから引用)
学習
SDXLの論文によると、学習は以下のように3段階で実行される。
| 段階 | 画素数 | batch size | steps | Offset-Noise |
|---|---|---|---|---|
| 1 | 256x256にcrop | 2048 | 600,000 | 0 |
| 2 | 512x512にcrop | ? | 200,000 | 0 |
| 3 | 約1024²の複数のBucket | ? | ? | 0.05 |
データセットの仕様は不明。
Refinerの学習のために美的スコアを入力する必要があるので、LAION-Aestheticsなどのデータセットを含んでいるものと思われる。
AUTOMATIC1111での使い方
AUTOMATIC1111では2023年8月31日のバージョン1.6.0で利用可能となった。
モデルのダウンロード
学習済みのSDXL 1.0のモデルファイルは以下からダウンロードすることができる。
(Hugging Faceへのアカウント登録が必要)
- stabilityai/stable-diffusion-xl-base-1.0 · Hugging Face
- stabilityai/stable-diffusion-xl-refiner-1.0 · Hugging Face
- stabilityai/sdxl-vae · Hugging Face
ダウンロードしたファイルは以下のフォルダーに配置する。
- base・refiner→「stable-diffusion-webui/models/Stable-diffusion」
- vae→「stable-diffusion-webui/models/VAE」
web UIの操作
Stable Diffusion checkpointに「sd_xl_base_1.0.safetensors」を指定。
SD VAEに「sdxl_vae.safetensors」を指定。
(SD VAEの設定項目が表示されていない場合は、「Settings」→「User interface」→「Quicksettings list」に「sd_vae」を追加してweb UIを再起動することで表示される)
「Refiner」を開き、Checkpointに「sd_xl_refiner_1.0.safetensors」を指定。
Switch atは生成過程の中でどの割合のタイムステップでBaseからRefinerに切り替えるかという値。SDXLの論文ではRefinerは200ステップ分に特化すると書かれているので、ここでは0.8を指定してBaseに8割・Refinerに2割を担当させる。
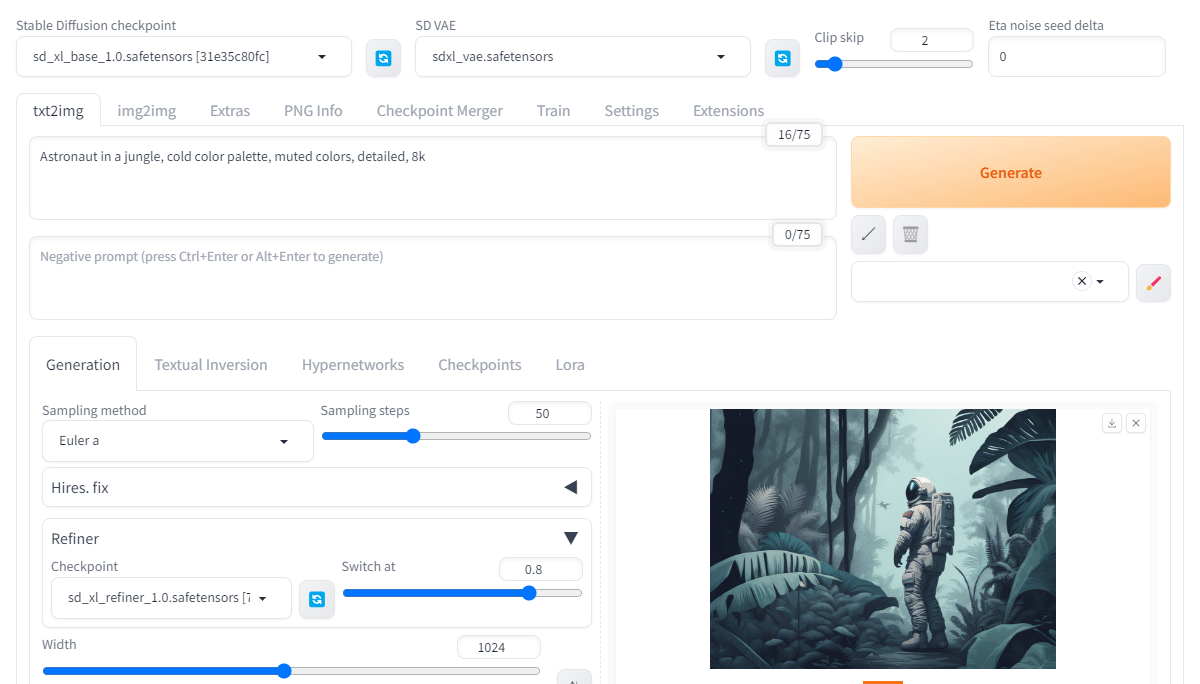
AUTOMATIC1111 1.6.0でのSDXLの設定

SDXLで生成した画像
参考
- [2307.01952] SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
- GitHub - Stability-AI/generative-models: Generative Models by Stability AI
- SDXL 1.0 をリリースしました — Stability AI Japan — Stability AI Japan
- NovelAI Improvements on Stable Diffusion | by NovelAI | Medium
- GitHub - NovelAI/novelai-aspect-ratio-bucketing: Implementation of aspect ratio bucketing for training generative image models as described in: https://blog.novelai.net/novelai-improvements-on-stable-diffusion-e10d38db82ac
- Diffusion With Offset Noise