Stable Diffusionのモデル構造
この記事では、Stable Diffusionの概要とソースコードから読み取ったモデル構造を解説する。
関連記事
目次
Stable Diffusion
Stable Diffusion(SD)は2022年8月22日に公開された拡散画像生成モデル。文章を入力すると、その文章に沿った内容の画像を出力することができるモデル。
ミュンヘン大学のCompVisチーム、イギリスのStability AI社、アメリカのRunway社が開発に携わった。
20億組以上の画像と英語の文章のペアで構成されるデータセット「LAION-2B」や、その中から推定美的スコアの高い画像だけを抜き出した「laion-aesthetics v2 5+」によって学習された。
Stable Diffusion以前の拡散画像生成モデルであるOpenAIの「DALL·E 2」(2022/04)、Googleの「Imagen」(2022/05)、Midjourney社の「Midjourney」(2022/07)とは異なり、上記の学習済みモデル(パラメーターファイル)が一般に公開されていて、個人が所有できるレベルのマシンでも推論・学習ができることが特徴。これにより、研究者ではなくてもStable Diffusionをローカルで動作させることが可能となり、Stable Diffusionを扱うネットコミュニティが各所に生まれ、様々な新技術や応用テクニックが編み出されている。
Stable Diffusionのモデル構造
Stable Diffusion Version 1のソースコードからモデル構造を調べた。
画像内の数値は設定ファイル「v1-inference.yaml」に準拠する。
全体図
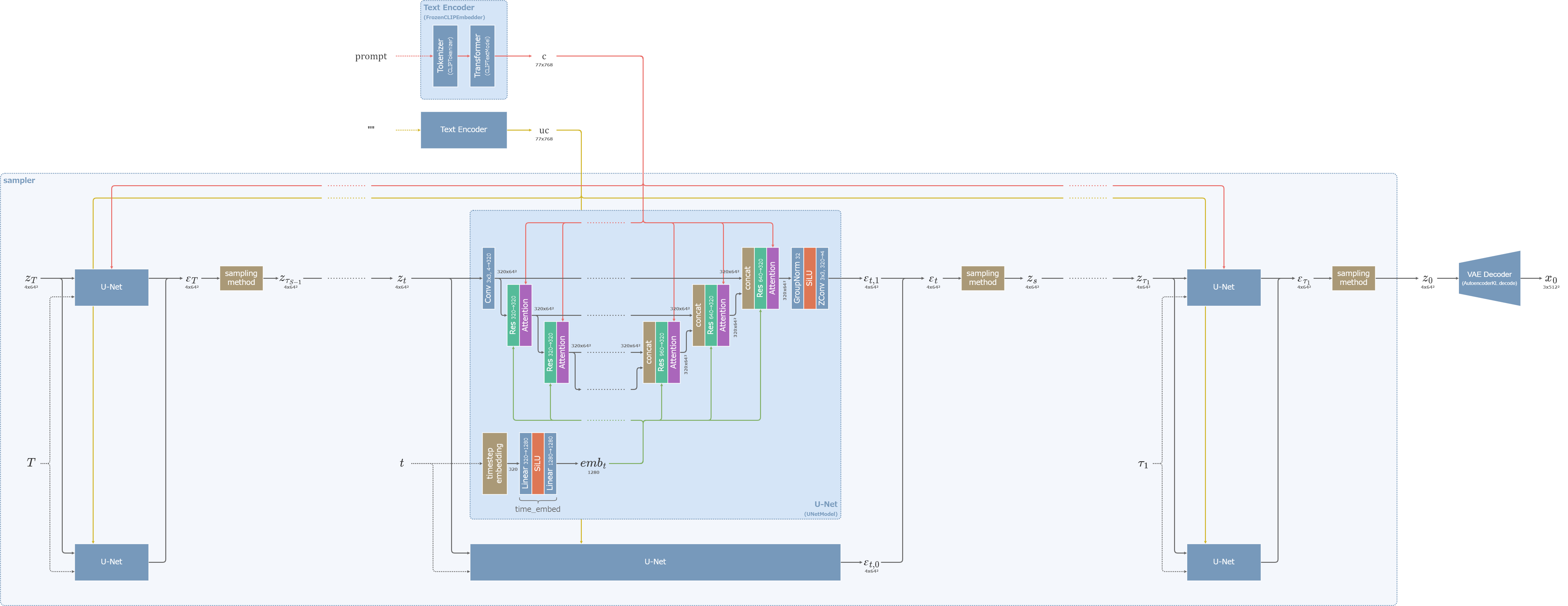
Stable Diffusionの生成過程の全体像 (クリックで拡大)
Stable Diffusionは主に以下の3つのモデルで構成される。
- ノイズ\(\varepsilon\)を推論する拡散モデルU-Net
- 入力文章を潜在ベクトルへと変換するText Encoder(TE)
- U-Netで扱う画像潜在ベクトルとRGB画像を相互に変換するVAE Encoder・VAE Decoder
Stable Diffusionは2021年にCompVisチームが公開したLDMに基づいた実装となっている。画像と画像潜在ベクトルへとの変換は、(v1-inference.yamlの設定の場合)VAEを使って行われる。
拡散モデルはU-Netで実装され、OpenAIのCLIPで埋め込まれた文章の潜在ベクトルをCross-Attentionで受け取る。
また、CFGを利用するため、入力文章とは別に空の文字列を拡散モデルに入力し、それぞれの出力を足し合わせる仕組みが設けられている。
(v1-inference.yamlの設定の場合、)サンプラーにはDDIMが用いられ、ステップ数\(S=50\)で画像が生成される。
LDM・CLIP・CFG・DDIMについては前回の記事で解説している。また、VAEの理論についても過去の記事で解説している。
拡散モデル: U-Net
Stable Diffusionでは拡散モデルにU-Netが用いられる。
2015年に発表されたオリジナルのU-Netそのものではなく、U-Net型の構造を持つ独自のモデルとなっている。下図ではほとんどV字だが、モデル設計を図にしたときにU字になっていることからU-Netと名付けられている。
生成過程の全てのタイムステップで、同一のU-Netのパラメーターを共有して使用する。(つまり、タイムステップ毎に別のパラメーターを学習しているわけではない。)
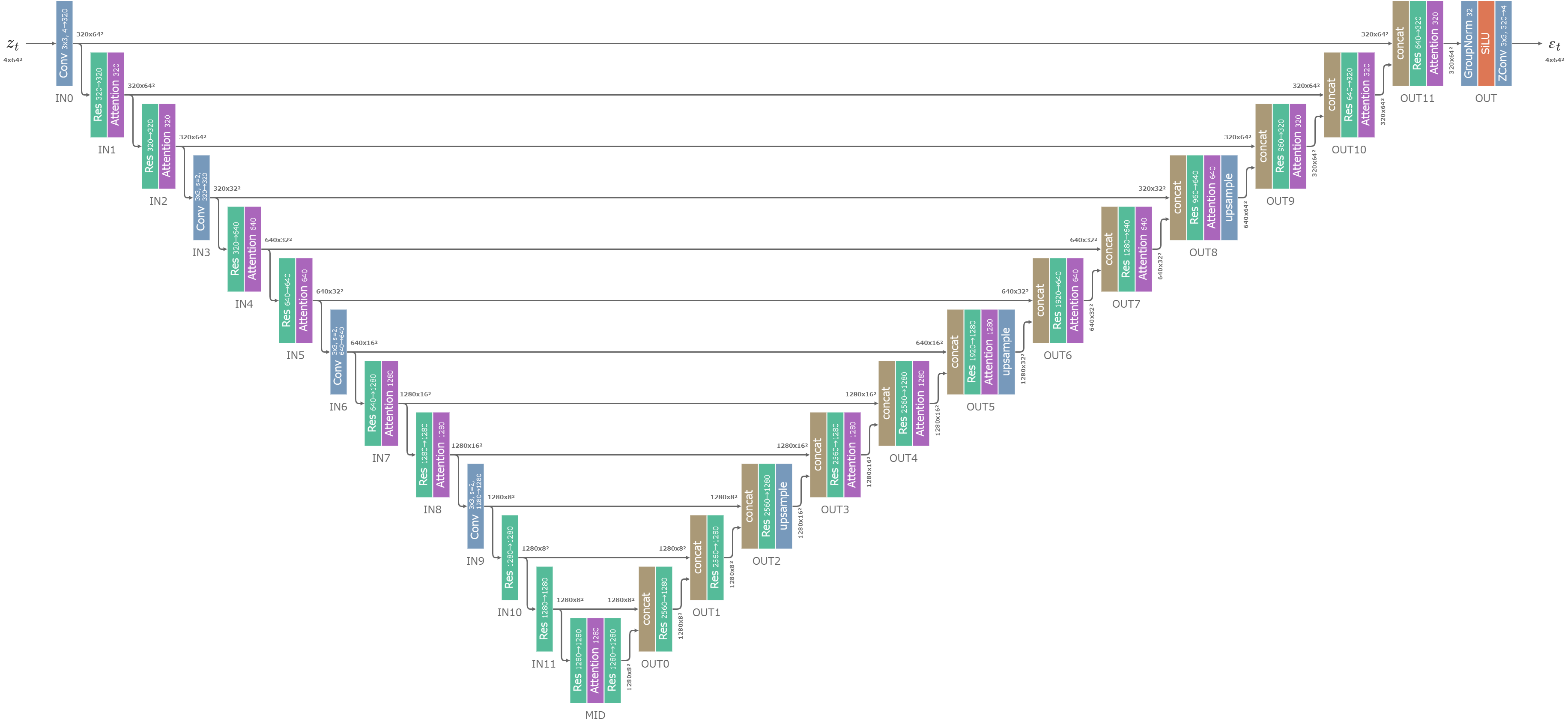
Stable DiffusionのU-Net (クリックで拡大)
図中で、全てのResブロックは時間埋め込み\(emb_t\)を受け取り、全てのAttentionブロックは文章埋め込み\(c\)あるいは\(uc\)を受け取る。
Resブロック
U-NetのResブロックはResNet (2015)で提案された残差ブロックを元にした層。
時間の埋め込みベクトル\(emb_t\)を受け取り、Resブロックごとに持つ1層の重みで変換した後に加算される。
Resブロックで次元を変換する場合(\(C\neq C_o\)となる場合)は、skip connection側にも層を追加して次元を合わせる。

Stable DiffusionのU-NetのResBlock (\(C=C_o\)の場合)
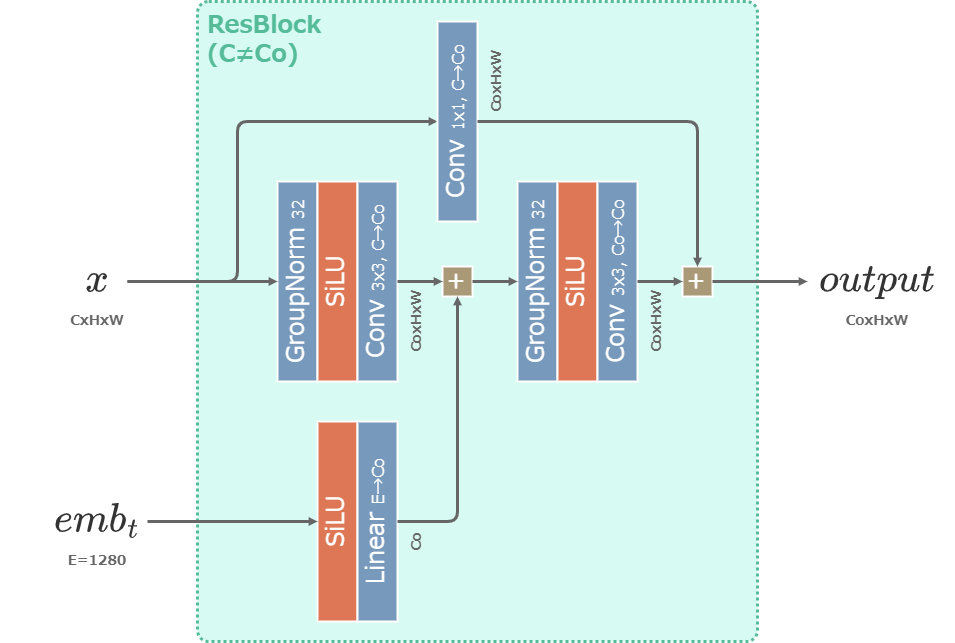
Stable DiffusionのU-NetのResBlock (\(C\neq C_o\)の場合)
SiLUは次の式で表される活性化関数。Swishとも呼ばれる。
\begin{align} SiLU(x) := x\sigma(x) = \frac{x}{1+\exp(-x)} \end{align}
時間埋め込み
時間埋め込みベクトルは、下図のように生成される。
U-Net1回の実行に対して\(emb_t\)は1度だけ生成され、全てのResブロックに同じ値が入力される。

Stable Diffusionの時間埋め込み層
timestep embeddingは次のように実行される。
\begin{align} timestep\_embedding(t) := \begin{pmatrix} \cos(t\cdot 10000^{-\frac{0}{160}}) \\ \vdots \\ \cos(t\cdot 10000^{-\frac{159}{160}}) \\ \sin(t\cdot 10000^{-\frac{0}{160}}) \\ \vdots \\ \sin(t\cdot 10000^{-\frac{159}{160}}) \\ \end{pmatrix} \end{align}
Attentionブロック
U-NetのAttentionブロックにはTransformer (2017) のDecoderを元にした構造のモデルが用いられる。
Cross-Attentionで文章の埋め込みベクトルを受け取る。
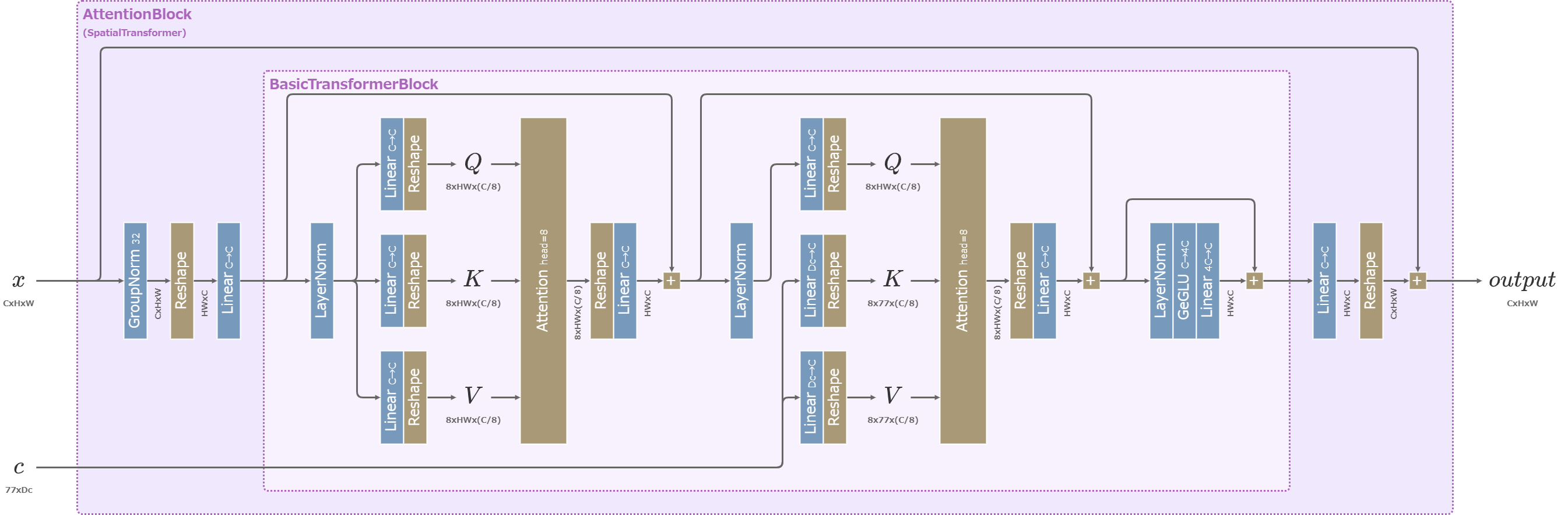
Stable DiffusionのU-NetのAttentionBlock
3つの行列\((Q,K,V)\)はAttention層に入る前にチャンネル次元\(C\)を8つに分解する。
Attention層では分割された8組の行列\((Q,K,V)\)ごとに次のように計算し、出力された8つの結果をconcatで結合して出力する。(一般にはその前後のLinear層を含めてAttention層と呼ぶので注意)
\begin{align} Attention(Q, K, V) := softmax\left(\frac{QK^\top}{\sqrt{C/8}}\right)V \end{align}
GeGLUは次の式で表されるパラメーターのある活性化関数。
\begin{align} GeGLU(x) &:= Linear_1(x)GELU(Linear_2(x)) \\ &= Linear_1(x)Linear_2(x)\Phi(Linear_2(x)) \\ &= Linear_1(x)Linear_2(x)\frac{1}{2}\left(1+erf\left(\frac{Linear_2(x)}{\sqrt{2}}\right)\right) \end{align}
Upsample層
U-Netの図でUpsampleと表記した層は、次のように2倍の解像度に拡大した後に3x3の畳み込み層を作用させる。
拡大には最近傍法が用いられる。
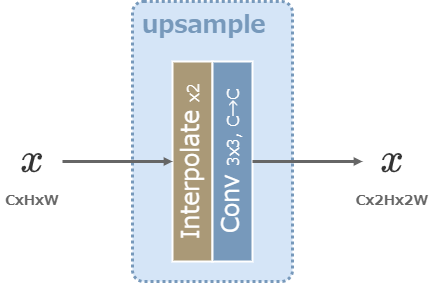
Stable DiffusionのUpsample層
Text Encoder: CLIP
Text EncoderにはCLIPが用いられる。
実装にはHuggingfaceのtransformersパッケージに含まれるCLIPTokenizer, CLIPTextModelが使われている。

CLIPTokenizerは文字列型の文章を受け取り、文章を単語に分割し、予め定義された辞書に従って整数型のIDに変換する働きを担う。
CLIPTextModelでは、単語IDと単語位置をそれぞれ学習可能なベクトルに埋め込み、その和を12層のTransformer Encoderに入力する。
QuickGELUは、GELUの論文に掲載されているGELUの近似関数。
\begin{align} QuickGELU(x) &:= x\sigma(1.702x) \\ &= \frac{x}{1+\exp(-1.702x)} \end{align}
Autoencoder: VAE
オートエンコーダーにはVAEが用いられる。
Stable DiffusionのVAEは次のように、主にResブロックで構成される。

Stable DiffusionのVAE Encoder

Stable DiffusionのVAE Decoder
Resブロック
VAEのResブロックはU-Netのものとほぼ同じで、時間埋め込みを受け取らない点のみ異なる。

Stable DiffusionのVAEのResBlock (\(C=C_o\)の場合)
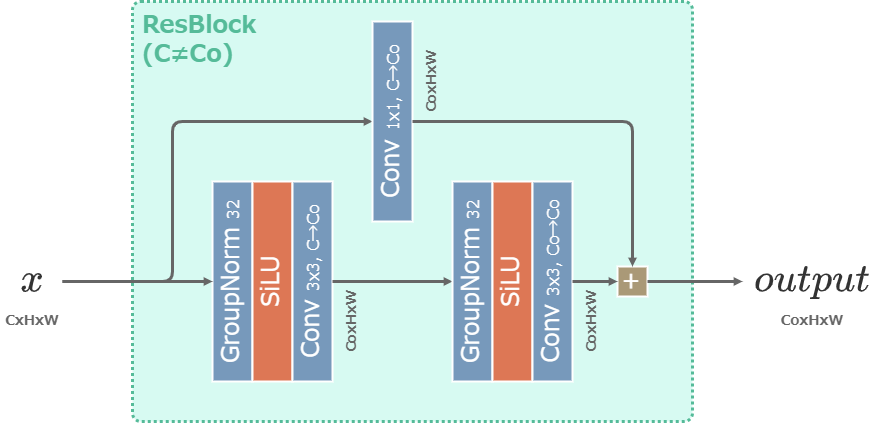
Stable DiffusionのVAEのResBlock (\(C\neq C_o\)の場合)
Attentionブロック
VAEのAttentionブロックはU-Netのものより簡素な構造を持つ。
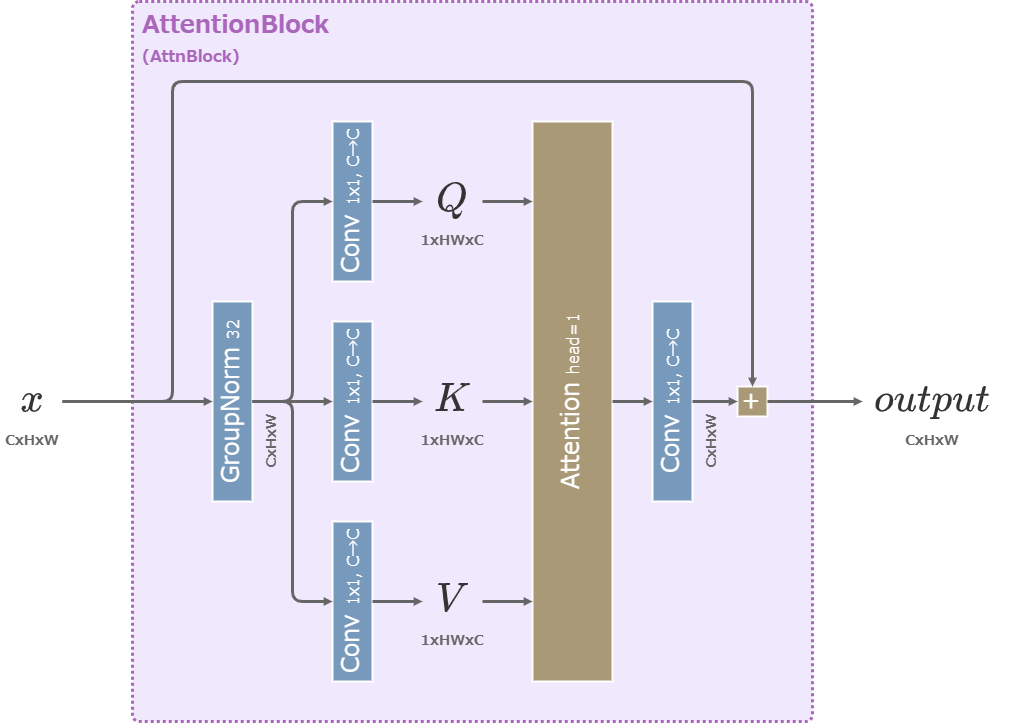
Stable DiffusionのVAEのAttentionブロック
参考
- GitHub - CompVis/stable-diffusion: A latent text-to-image diffusion model (Stable Diffusion Version 1)
- GitHub - Stability-AI/stablediffusion: High-Resolution Image Synthesis with Latent Diffusion Models (Stable Diffusion Version 2)
- transformers.models.clip.modeling_clip — transformers 4.7.0 documentation (CLIP)
- GitHub - AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI
- 誰でもわかるStable Diffusion その4:U-Net - 人工知能と親しくなるブログ
- Stable Diffusion UNET 结构 - 知乎